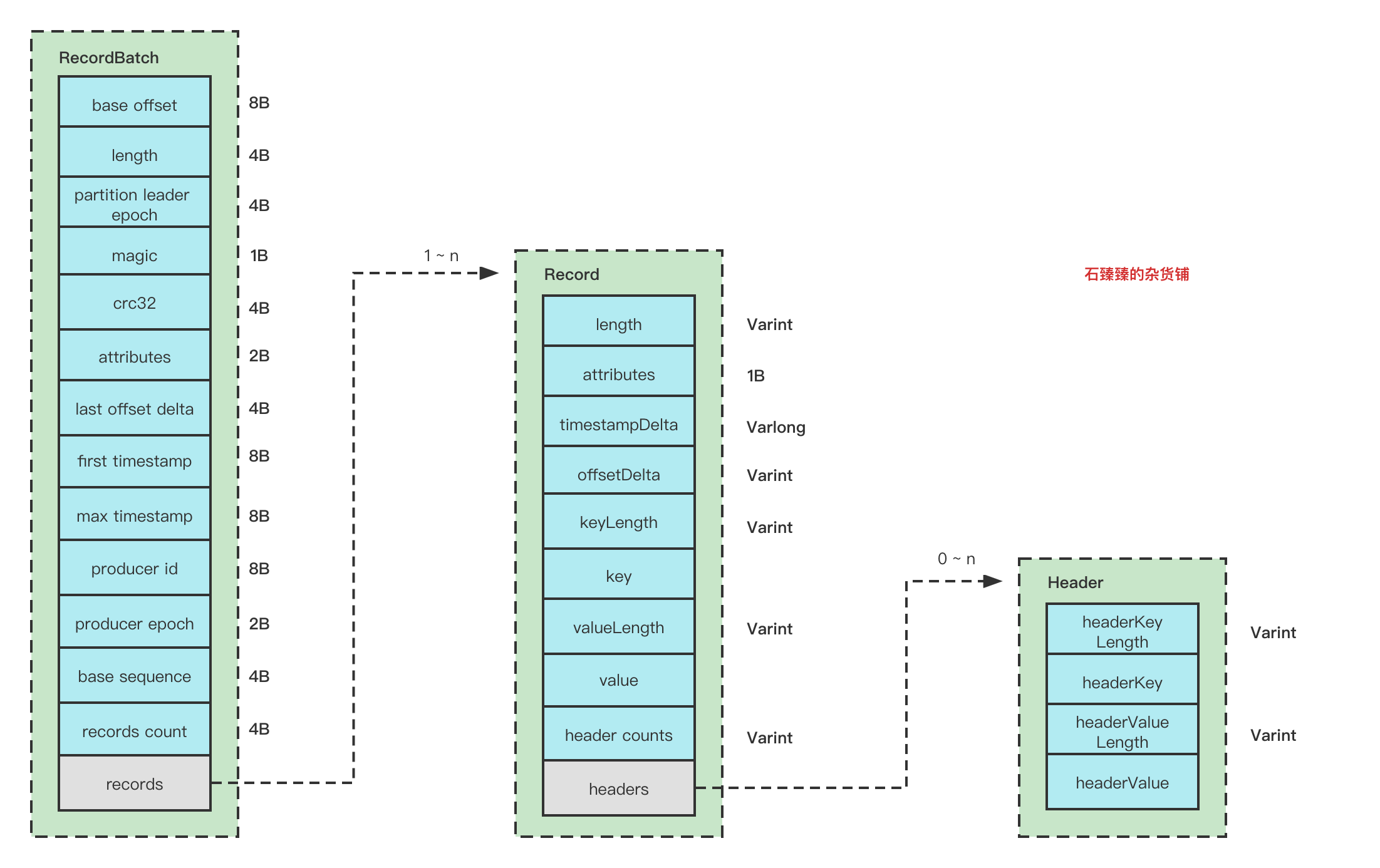
分区副本同步限流机制三部曲(源码篇)
kafka管控推荐使用 滴滴开源 的 Kafka运维管控平台 更符合国人的操作习惯 ,
更强大的管控能力 ,更高效的问题定位能力 、更便捷的集群运维能力 、更专业的资源治理 、 更友好的运维生态
这一篇我们主要来看看分区副本重分配限流是如何实现的,此源码分析基于kafka2.5版本。在开始之前我们先来回顾一下分区重分配的流程,如图一所示。
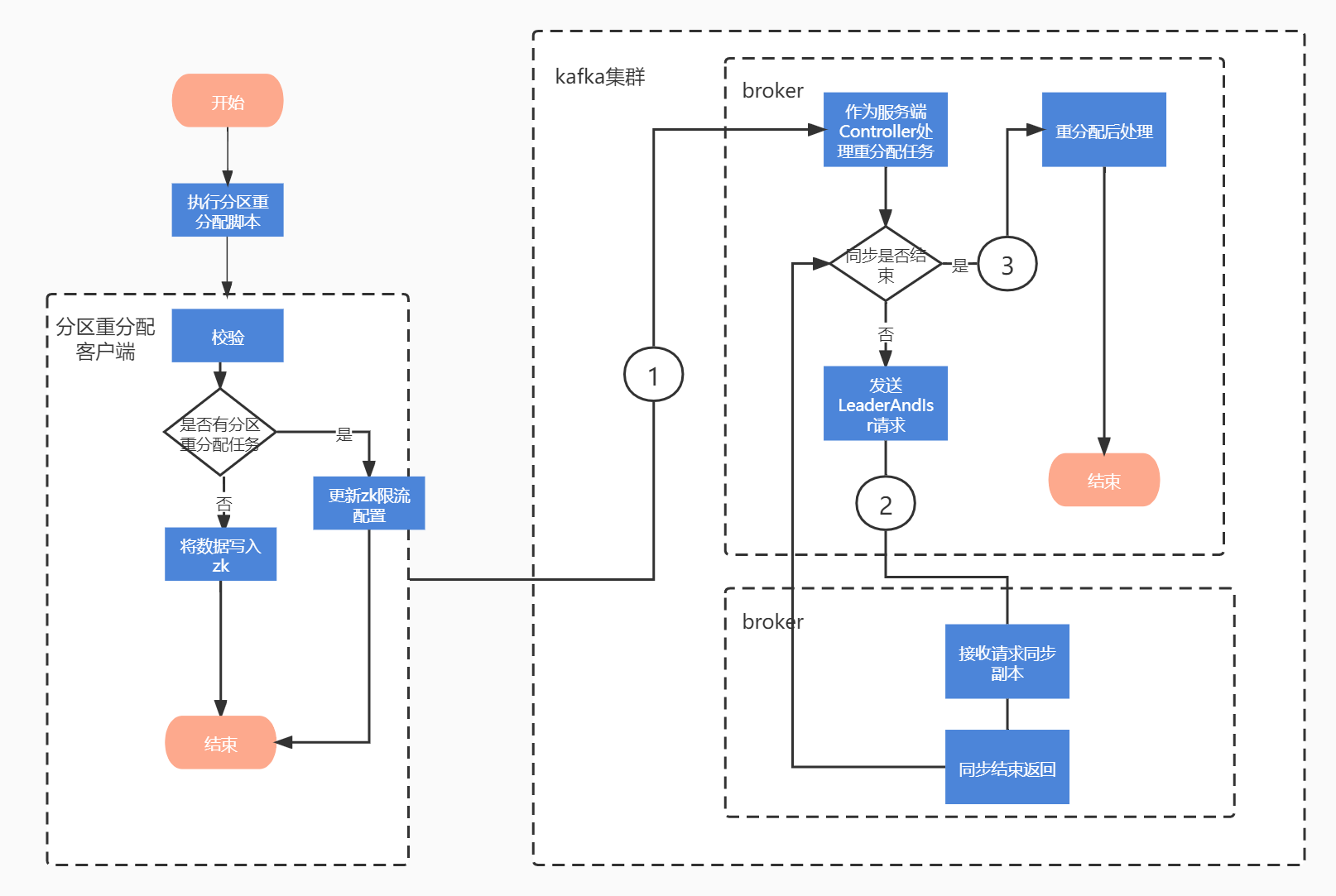
- 执行分区重分配脚本,这里相当于起了个kafka客户端,执行完脚本将重分配数据写入zk即返回了。
- kafkaController监听到zk分区重分配节点数据变动,会调相应的handler来处理数据,这里相当于kafka服务端大脑的角色,控制了分区重分配主要处理的流程,并发送命令给其他节点执行,描述的简单一点就是会根据重分配脚本在对应的broker
创建新的副本并删除需要移除的副本。 - 最后,kafkaController收到各个broker执行完操作的命令,会执行一些重分配结束后操作,包括修改zk
节点数据,更新元数据信息等。
大家也可以思考一下,如果把限流这个功能交给你,你会如何设计与开发?今天我们想聊的限流,就是在创建新的副本中实现的。在需要创建副本时,kafkaController会向对应的broker发送LeaderAndISRRequest请求,下面我们就从这里开始。
broker对LeaderAndIsr请求的处理
入口在kafka.server.KafkaApis.handleLeaderAndIsrRequest,处理LeaderAndIsrRequest
请求的代码就不放了,处理也比较简单,因为我们现在是做分区重分配,是先增加副本然后再下线删除不要的副本,所以会走里面makeFollowers方法的逻辑,在makeFollowers
中主要就是建立对应的文件夹,然后启对应的ReplicaFetcherThread来跟leader通信拉取数据,下面我们主要来分析一下ReplicaFetcherThread的代码。
这里主要就是构建FetchRequest然后处理FetchResponse,如果fetchRequestOpt为空,则会让线程等待一秒,
1 | private def maybeFetch(): Unit = { |
构建同步数据request代码分析
在这里,我们看到了关键代码shouldFollowerThrottle,下面我们进入到这个方法,看是如何实现限流的。
1 | override def buildFetch(partitionMap: Map[TopicPartition, PartitionFetchState]): ResultWithPartitions[Option[ReplicaFetch]] = { |
shouldFollowerThrottle源码分析
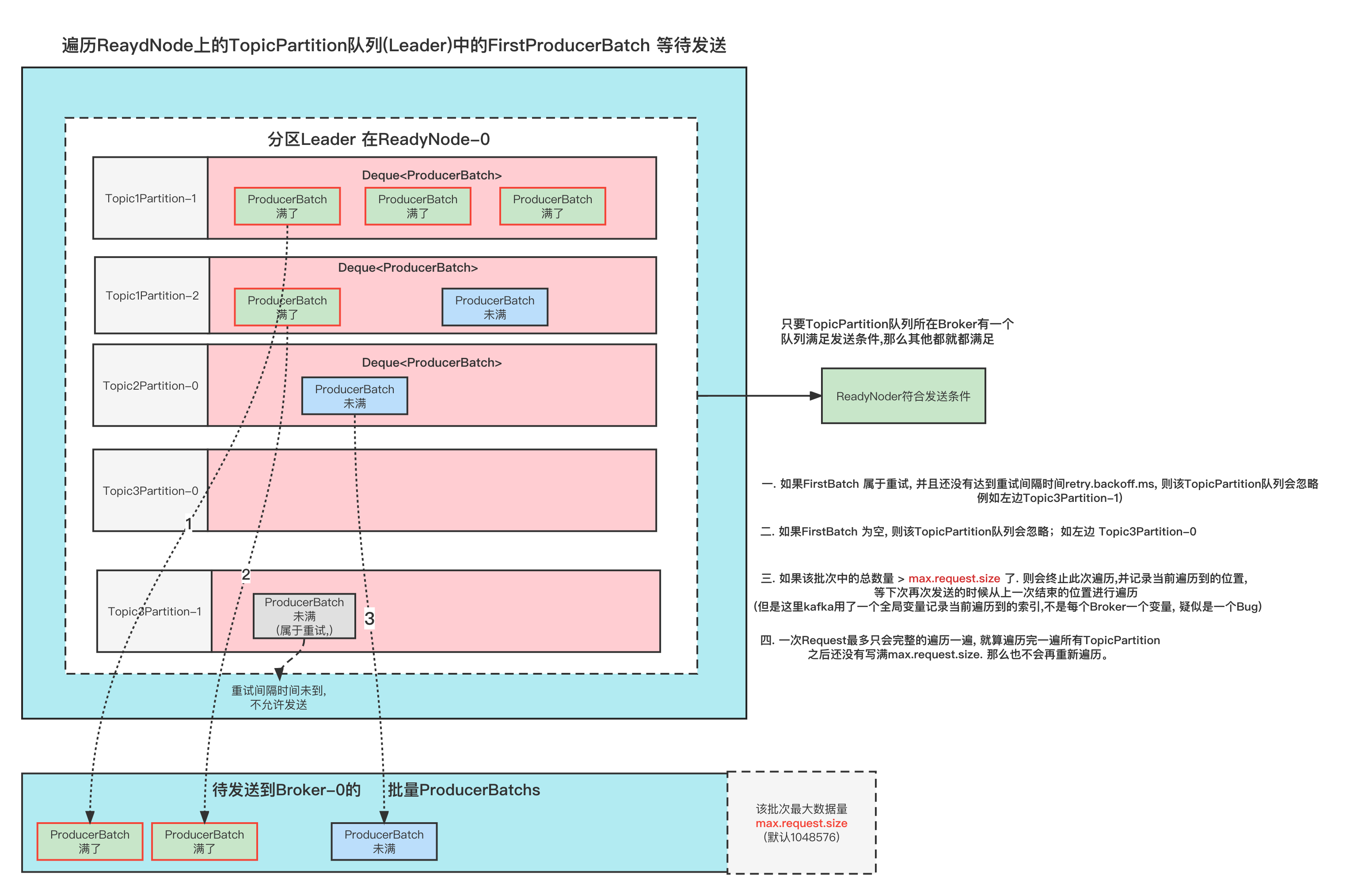
这里代码实际很简单,有三个判断,第一个是判断副本是否同步,如果没同步则!fetchState.isReplicaInSync为true。第二个会去判断topicPartition是否在限流的内存配置中,这里的内存配置就是在分区重分配第一步时,将配置数据写入zk后触发的。第三个就是真正的限流了,判断是否达到阙值。
如果达到zk中设置的阙值,就会返回false,fetchData就会为空,在外层代码中会使等待一秒再重新请求。
1 | private def shouldFollowerThrottle(quota: ReplicaQuota, fetchState: PartitionFetchState, topicPartition: TopicPartition): Boolean = { |
在leader端同理,leader所在的broker会接收Fetch请求,入口在kafka.server.KafkaApis#handleFetchRequest,里面也有一段类似的代码,如下
1 | val shouldLeaderThrottleResult = shouldLeaderThrottle(quota, tp, replicaId) |
限流的实现
从上面的代码分析我们知道了限流是在哪一步代码中控制的,却不知道是怎么实现的,这里我们单独来讲解一下,具体见图二
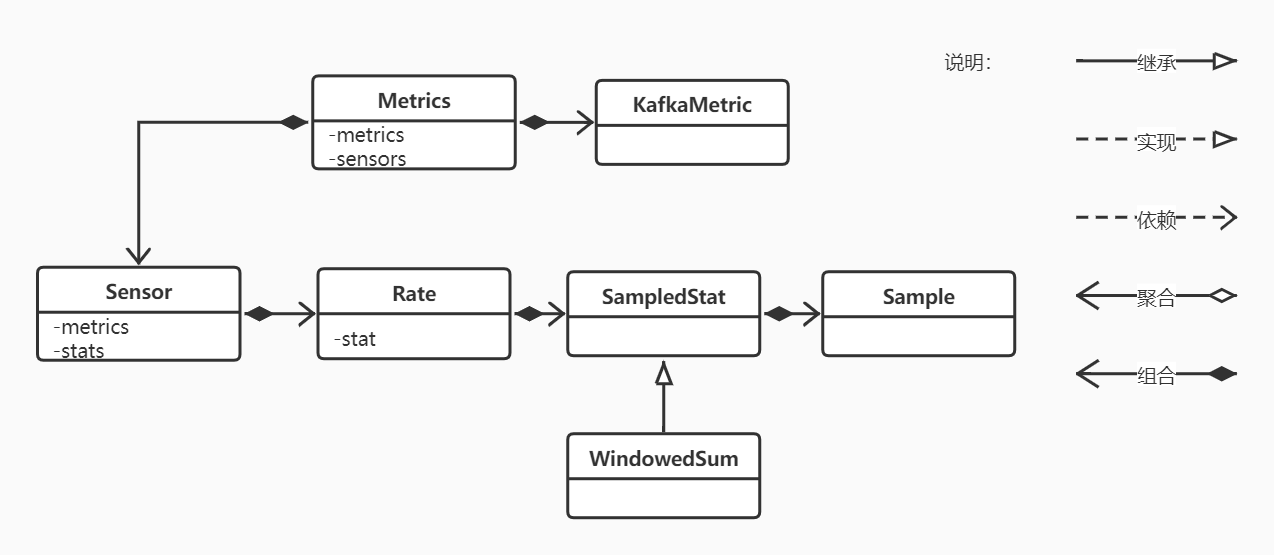
Metrics及KafkaMetric类说明
这里我只画出了简单的组合关系,限流有关的是从Metrics类开始的,Metrics类相当于全局的限流工厂类,里面有两个ConcurrentMap分别装载KafkaMetric及Sensor,我们先来看看KafkaMetric
,里面主要就是初始化一些参数,然后提供获取当前值的方法,KafkaMetric的作用就是对一种限流类型的封装。
1 | double measurableValue(long timeMs) { |
在Kafka服务端启动时会初始化一个全局的Metrics及QuotaManagers限流信息管理类,可以看到QuotaFactory.instantiate中分别初始化了leader及follower的限流管理类,QuotaManagers或者是ReplicationQuotaManager对象就会一层一层作为入参传入到其他方法使用,是单例的。
1 | def startup(): Unit = { |
Sensor类说明
对于Sensor,这个类的作用就比较多了,代码如下,由于篇幅的关系这里并没有放完整的代码,这里提供了两个重要的方法,一个是record,会在关键代码处调用此方法记录流量值,另一个是checkQuotas
,判断是否达到阙值,这里可能会有小伙伴疑惑,为什么在Metrics类中装载了KafkaMetric,而Sensor又有个Map<MetricName, KafkaMetric>
metrics对象,可以这样理解,Metrics中装载的是所有的KafkaMetric对象,而在Sensor中是针对一种记录值特有的限制。
1 | public final class Sensor { |
Sensor#record的实现
代码在SampledStat的record方法中,代码的逻辑我已注解,主要就是根据传入的时间获取当前样本对象,如果超出了config
中配置的值,则增加样本,否则更新样本数据。这里要特别说明一下,样本的数量及是否增加样本的时间都是在MetricConfig初始化的时候传入的,样本数量是samples默认为11,可通过配置replication.quota.window
.num来修改,样本时间是timeWindow,默认为1秒,可以通过replication.quota.window.size.seconds配置来修改。
1 | public void record(MetricConfig config, double value, long timeMs) { |
Sensor#checkQuotas的实现
前面我们知道在checkQuotas中主要就是获取当前的流量值与配置的比对,而计算当前流量值就是在Rate#measure方法中实现的,在measure方法里面主要是会调用SampledStat#measure,在SampledStat#measure方法中会调用purgeObsoleteSamples
方法来重置过期的副本,然后再调用具体的combine方法,我们这里combine调用的是在WindowedSum中实现的,也就是循环各个样本累加在一起,回到Rate#measure
中,发现逻辑无非就是统计各个样本中的流量相加,然后除以时间来计算平均流量。
1 | //Rate#measure |
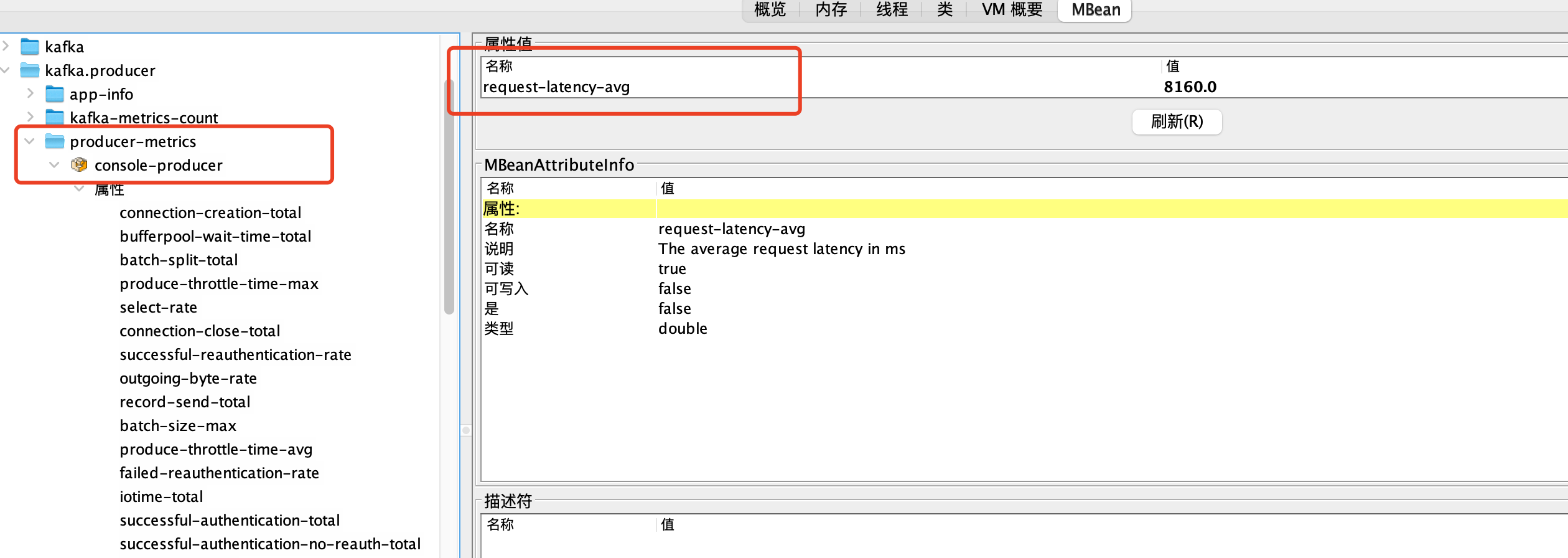
流量是在哪儿记录的?
相信读到这里很多人都有这个疑问,在followers端是在FetchResponse返回的时候记录的,代码见图三
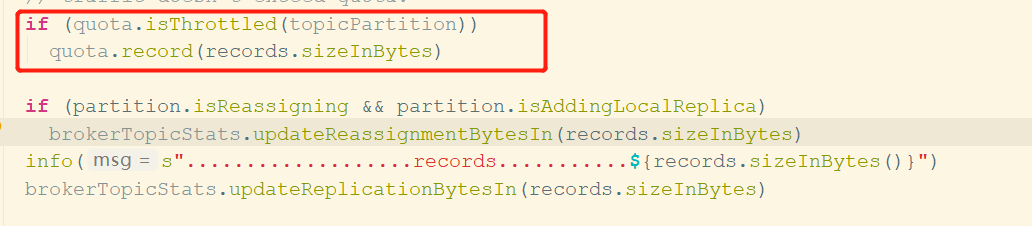
在leader端,是在读完日志文件之后会记录流量值

可以看到在follower端需要判断是否在限流副本中才记录流量值,而在leader端则在计算Fetch返回大小的时候就已经过滤掉了不需要计算的副本的流量值了
也会被记录流量值,不太能猜到这样做的意图。
在这里我们也可以梳理一下Kafka限流的实现原理:
1、在broker启动的时候初始化限流管理类及全局的限流配置。
2、如果在zk节点中写入了leader及follower的限流配置,则会在同步副本时调用方法isQuotaExceeded来判断是否达到限流值,在这里我还想说明一下为什么在zk中写入leader.replication
.throttled.replicas数据时为什么要包含原来所有的副本,因为在同步新副本的时候leader有可能会掉线然后重新选举leader,所以不如一次性全写入。
3、如果没有达到限流值则会在对应的地方分别记录流量,leader与follower的流量值是分开记录的。
4、判断是否达到限流值的方式就是记录最近一定数量的样本并计算平均值。
对于限流的几点思考
学到这里可能大家对限流代码逻辑有了一个基本的认识,我们下面就通过几个问题来让大家加深印象。
设置限流值为1是否永远都无法完成分区重分配任务?
不完全是,可以设想一下,如果副本数据小于一次fetch的值,leader跟follower之前也完全没有流量记录,那一次同步之后就结束了,样本那也只能记录一下这次的流量,但达到完全没有流量记录是十分苛责的,只存在于demo
版的kafka,在follower端还可以达到,而在leader端,根据我的测试,平常完全没有数据的一次fetch也会返回18k的流量,一秒大概是36k的数据,所以如果数据大于一次fetch的上限,那在之后fetch的时候都会被leader端限制。我们在设置限流值的时候一定要考虑副本的日常流量,这点在官方文档上也有提及,如果小于日常流量的话那将无法完成迁移。
针对leader的测试
- 准备3个broker,topic_1与topic_2,leader都在broker1上,topic_1迁移到broker2上,topic_2迁移到broker3上,副本数据为200M,限流值设置为300*1024b/s即300k/s
- 结果如下,200M = 2001024k,2001024k/300k/60≈11.37min,因为有两个topic都需要迁移,且leader端限制了传输速率,所以最终迁移持续时间大概为19分钟
1
2
3
4
5[controller-event-thread] INFO kafka.controller.KafkaController - [Controller id=1] reassignment :Map(topic_1-0 -> ReplicaAssignment(replicas=1,2, addingReplicas=2, removingReplicas=), topic_2-0 -> ReplicaAssignment(replicas=1,3, addingReplicas=3, removingReplicas=)) start at 2021-11-13 13:18:20
......
[controller-event-thread] INFO kafka.controller.KafkaController - [Controller id=1] No more partitions need to be reassigned. Deleting zk path /admin/reassign_partitions at 2021-11-13 13:37:31针对follower的测试
- 准备3个broker,topic_1与topic_2,topic_1的leader在broker1上,topic_2的leader在broker2上,均迁移到broker3,副本数据为200M,限流值设置为300*1024b/s
- 结果如下,这里跟上一个例子一样,原本只需要11分钟左右的,因为有两个topic都需要迁移,follower端限制了传输速率,所以最终迁移持续时间有21分钟
1
2
3
4
5
6[controller-event-thread] INFO kafka.controller.KafkaController - [Controller id=1] reassignment :Map(topic_1-0 -> ReplicaAssignment(replicas=1,3, addingReplicas=3, removingReplicas=), topic_2-0 -> ReplicaAssignment(replicas=2,3, addingReplicas=3, removingReplicas=)) start at 2021-11-13 14:22:42
......
[controller-event-thread] INFO kafka.controller.KafkaController - [Controller id=1] No more partitions need to be reassigned. Deleting zk path /admin/reassign_partitions at 2021-11-13 14:43:17限制互不影响的测试
- 准备3个broker,topic_1与topic_2,topic_1的leader在broker1上,topic_2的leader在broker2上,topic_1迁移到broker2,topic_2迁移到broker3
副本数据为200M,限流值设置为300*1024b/s - 结果如下,可以看到leader与follower的针对不同topic互不影响的情况下就是11分钟完成迁移。
1
2
3
4
5[controller-event-thread] INFO kafka.controller.KafkaController - [Controller id=1] reassignment :Map(topic_1-0 -> ReplicaAssignment(replicas=1,2, addingReplicas=2, removingReplicas=), topic_2-0 -> ReplicaAssignment(replicas=2,3, addingReplicas=3, removingReplicas=)) start at 2021-11-13 15:04:37
......
[controller-event-thread] INFO kafka.controller.KafkaController - [Controller id=1] No more partitions need to be reassigned. Deleting zk path /admin/reassign_partitions at 2021-11-13 15:15:40如何估算集群迁移总流量?
我给出的意见是分别取所有leader跟follower的并集并去重计算个数,分别乘以限流值,然后取小值来估算。即sum = Math.min(leader,follower)*throttle。
关于kafka的限流实现机制是跟你设想的一样吗?
我觉得kafka限流不仅是给了我们一种限流的实现方式,更是教会我们如何拆分功能,这套就完全是跟kafka主要功能分离的,对外只提供关键方法,然后在关键代码处记录流量值,这也是我们在平常开发与设计中需要学习的。
最后关于kafka源码学习的几点建议
- 首先建议大家先了解scala的基本语法,虽然跟java比较像,但熟悉之后更容易读懂源码的意思。
- 建议大家学习kafka服务通信及副本机相关代码,这是两个比较独立的模块,在很多地方都有用到。
- 最后,kafka断点是非常难打的,很容易就会跟zk失联,所以要学会在关键处打上日志,并且耐心的分析源码。
作者石臻臻,工作8年的互联网老兵,丰富的开发和管理经验,全网「 粉丝数4万 」,
先后从事 「 电商 」、「 中间件 」、「 大数据」 等工作
现在任职于「 滴滴技术专家 」岗位,从事开源建设工作
目前在维护 个人公众号「 石臻臻的杂货铺 」 ; 关注公众号会有「 日常送书活动 」;
欢迎进「 高质量 」 「 滴滴开源技术答疑群 」 , 群内每周技术专家轮流值班答疑
可帮忙「 内推 」一二线大厂

 微信
微信

石臻臻的杂货铺
Java/大数据/中间件/教学视频