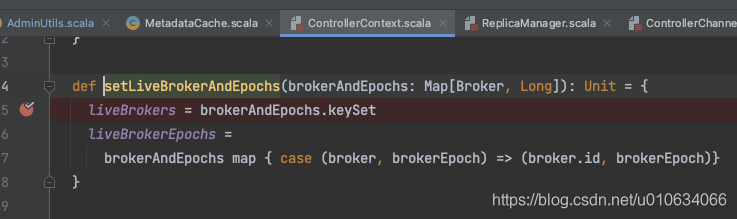
读完本篇文章,你可以再看关于分区分配规则的一个bug 关于分区副本分配相关的Bug...
源码分析 创建Topic的源码入口 AdminManager.createTopics()
以下只列出了分区分配相关代码其他省略
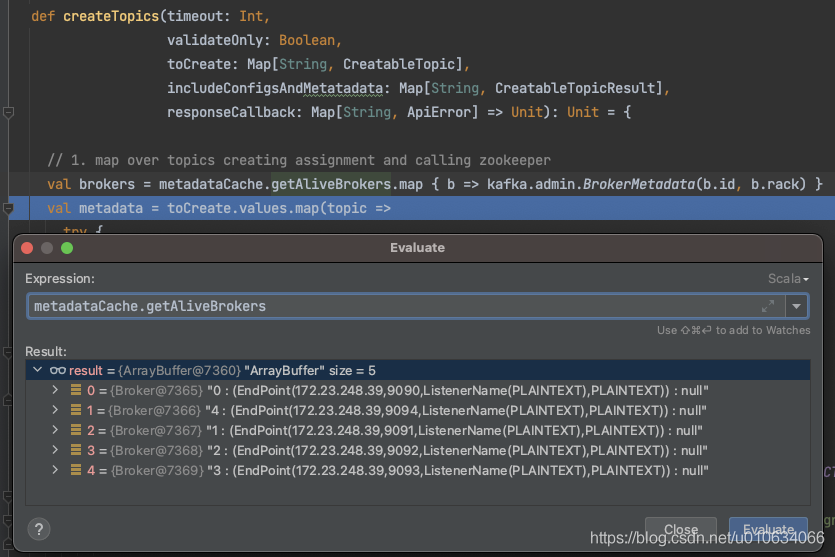
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def createTopics (timeout: Int, validateOnly: Boolean, toCreate: Map[String, CreatableTopic], includeConfigsAndMetatadata: Map[String, CreatableTopicResult], responseCallback: Map[String, ApiError] => Unit) : Unit val brokers = metadataCache.getAliveBrokers.map { b => kafka.admin.BrokerMetadata(b.id, b.rack) } val metadata = toCreate.values.map(topic => try { val assignments = if (topic.assignments().isEmpty) { AdminUtils.assignReplicasToBrokers( brokers, resolvedNumPartitions, resolvedReplicationFactor) } else { val assignments = new mutable.HashMap[Int, Seq[Int]] topic.assignments.asScala.foreach { case assignment => assignments(assignment.partitionIndex()) = assignment.brokerIds().asScala.map(a => a: Int) } assignments } trace(s"Assignments for topic $topic are $assignments " ) }
以上有两种方式,一种是我们没有指定分区分配的情况也就是没有使用参数--replica-assignment;一种是自己指定了分区分配
1. 自己指定了分区分配规则 从源码中得知, 会把我们指定的规则进行了包装,注意它并没有去检查你指定的Broker是否存在;
2. 自动分配 AdminUtils.assignReplicasToBrokers
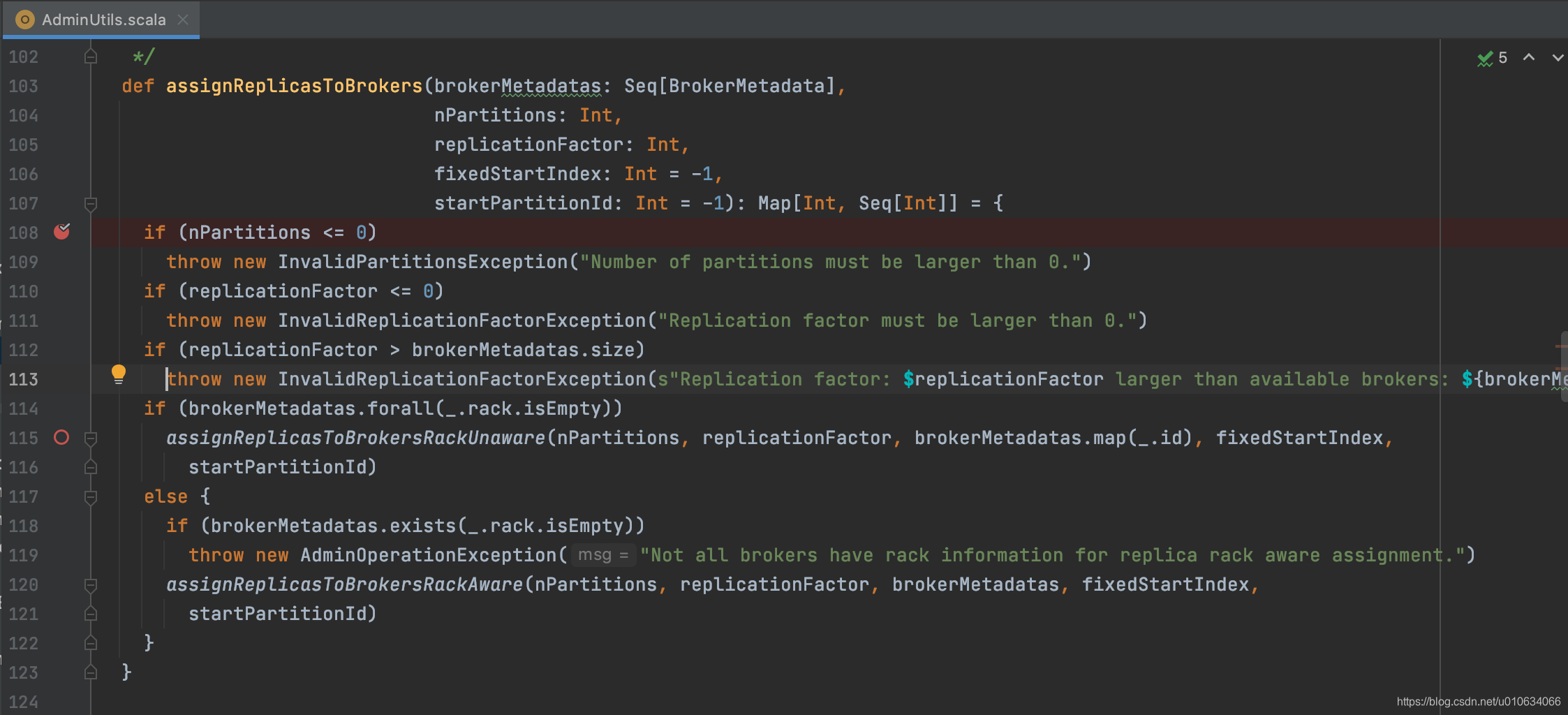
参数检查: 分区数>0; 副本数>0; 副本数<=Broker数 (如果自己未定义会直接使用Broker中个配置)
根据是否有 机架信息来进行不同方式的分配;
要么整个集群都有机架信息,要么整个集群都没有机架信息; 否则抛出异常
副本分配的几个原则:
将副本平均分布在所有的 Broker 上;
partition 的多个副本应该分配在不同的 Broker 上;
如果所有的 Broker 有机架信息的话, partition 的副本应该分配到不同的机架上。
无机架方式分配 AdminUtils.assignReplicasToBrokersRackUnaware
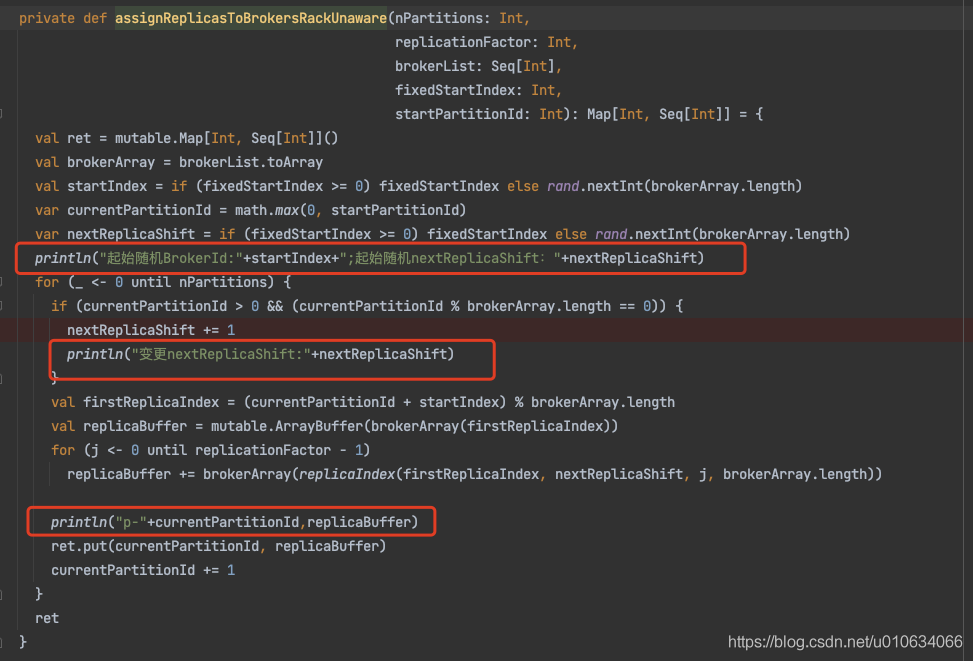
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 private def assignReplicasToBrokersRackUnaware Int , replicationFactor: Int , brokerList: Seq [Int ], fixedStartIndex: Int , startPartitionId: Int ): Map [Int , Seq [Int ]] = { val ret = mutable.Map [Int , Seq [Int ]]() val brokerArray = brokerList.toArray val startIndex = if (fixedStartIndex >= 0 ) fixedStartIndex else rand.nextInt(brokerArray.length) var currentPartitionId = math.max(0 , startPartitionId) var nextReplicaShift = if (fixedStartIndex >= 0 ) fixedStartIndex else rand.nextInt(brokerArray.length) for (_ <- 0 until nPartitions) { if (currentPartitionId > 0 && (currentPartitionId % brokerArray.length == 0 )) nextReplicaShift += 1 val firstReplicaIndex = (currentPartitionId + startIndex) % brokerArray.length val replicaBuffer = mutable.ArrayBuffer (brokerArray(firstReplicaIndex)) for (j <- 0 until replicationFactor - 1 ) replicaBuffer += brokerArray(replicaIndex(firstReplicaIndex, nextReplicaShift, j, brokerArray.length)) ret.put(currentPartitionId, replicaBuffer) currentPartitionId += 1 } ret } private def replicaIndex Int , secondReplicaShift: Int , replicaIndex: Int , nBrokers: Int ): Int = { val shift = 1 + (secondReplicaShift + replicaIndex) % (nBrokers - 1 ) (firstReplicaIndex + shift) % nBrokers }
从 broker.list 随机选择一个 Broker,使用 round-robin 算法分配每个 partition 的第一个副本;
对于这个 partition 的其他副本,逐渐增加 Broker.id 来选择 replica 的分配。
对于副本分配来说,每经历一次Broker的遍历,则第一个副本跟后面的副本直接的间隔+1;
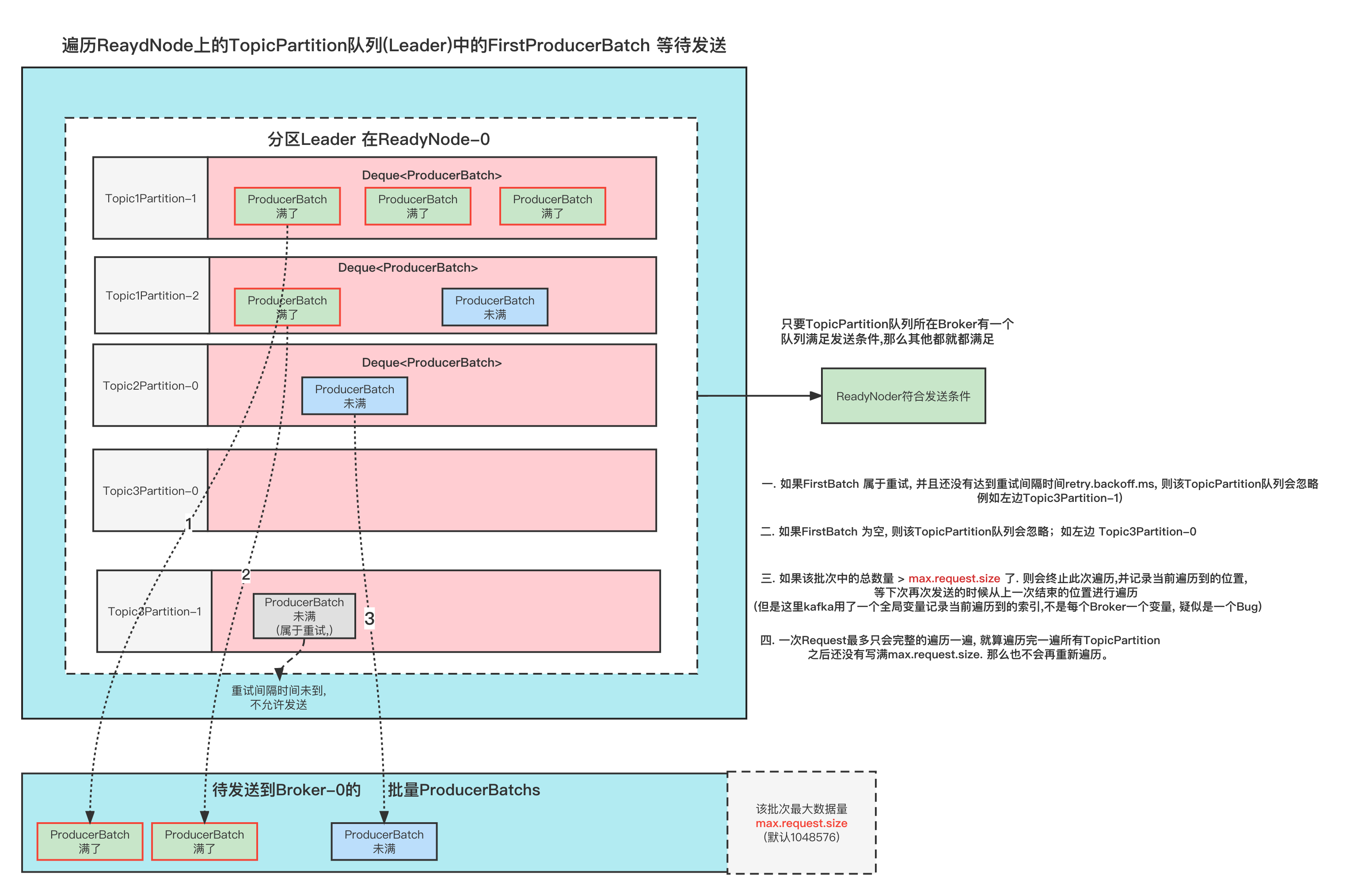
从代码和描述来看,可能理解不是很简单,但是下面的图我相信会让你非常快速的理解;
我们稍微在这段代码里面节点日志
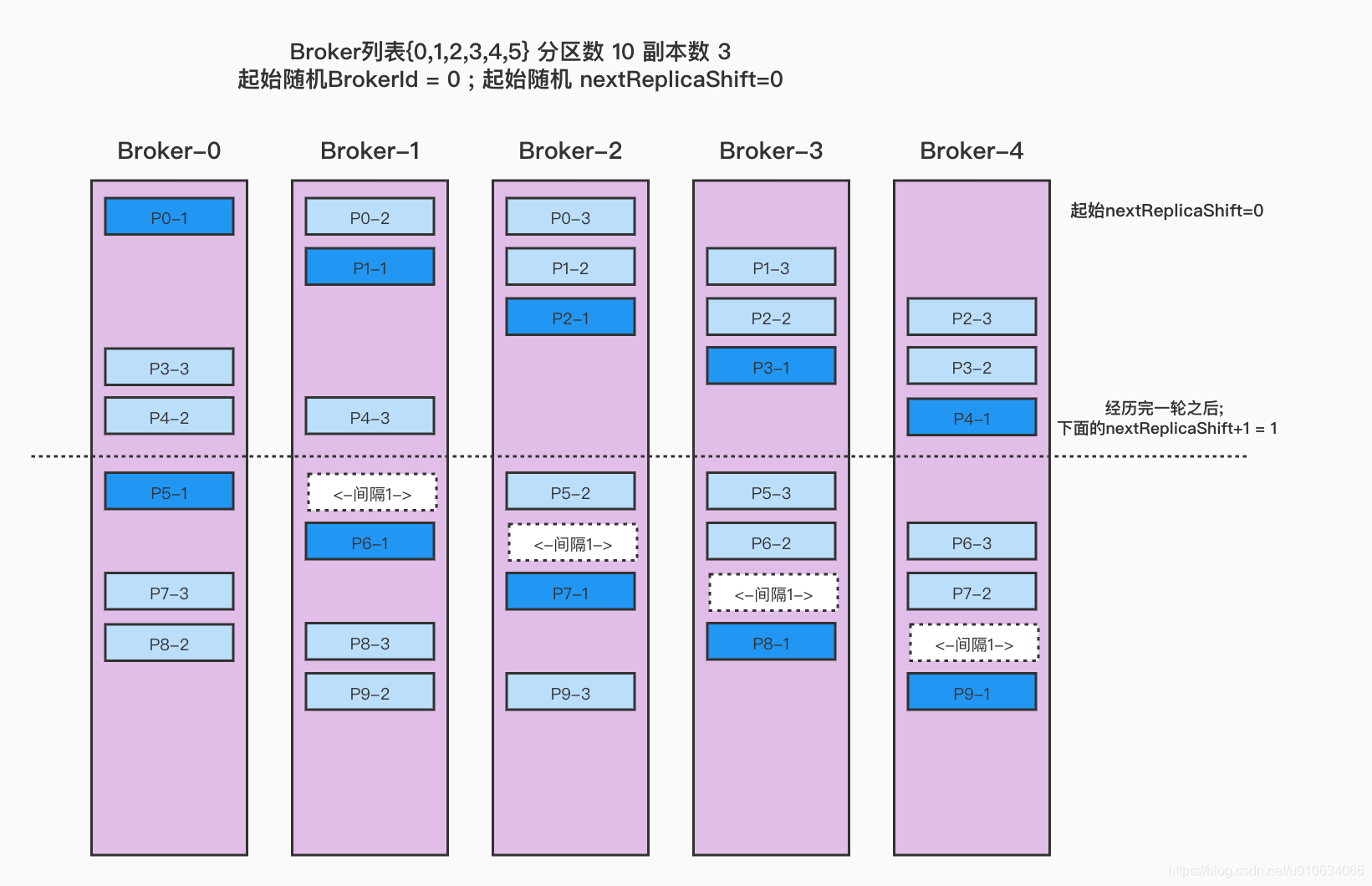
Broker列表{0,1,2,3,4} 分区数 10 副本数3 起始随机BrokerId=0; 起始随机nextReplicaShift=0 1 2 3 4 5 @Test def testReplicaAssignment2 Unit = { val brokerMetadatas = (0 to 4 ).map(new BrokerMetadata (_, None )) AdminUtils .assignReplicasToBrokers(brokerMetadatas, 10 , 3 , 0 ) }
输出:
1 2 3 4 5 6 7 8 9 10 11 12 起始随机startIndex:0;起始随机nextReplicaShift:0 (p-0,ArrayBuffer(0, 1, 2)) (p-1,ArrayBuffer(1, 2, 3)) (p-2,ArrayBuffer(2, 3, 4)) (p-3,ArrayBuffer(3, 4, 0)) (p-4,ArrayBuffer(4, 0, 1)) 变更nextReplicaShift:1 (p-5,ArrayBuffer(0, 2, 3)) (p-6,ArrayBuffer(1, 3, 4)) (p-7,ArrayBuffer(2, 4, 0)) (p-8,ArrayBuffer(3, 0, 1)) (p-9,ArrayBuffer(4, 1, 2))
看图
上面是分配的情况,我们每一行每一行看, 每次都是先把每个分区的副本分配好的;
最开始的时候,随机一个Broker作为第一个来接受P0; 这里我们假设随机到了 broker-0; 所以第一个P0在broker-0上; 那么第二个p0-2的位置跟nextReplicaShit有关,这个值也是随机的,这里假设随机的起始值也是0; 这个值意思可以简单的理解为,第一个副本和第二个副本的间隔;
因为nextReplicaShit=0; 所以p0的分配分别再 {0,1,2}
然后再分配后面的分区,分区的第一个副本位置都是按照broker顺序遍历的;
直到这一次的broker遍历完了,那么就要重头再进行遍历了, 同时nextReplicaShit=nextReplicaShit+1=1;
P5-1 再broker-0上,然后p5-2要跟p5-1间隔nextReplicaShit=1个位置,所以p5-2这时候在broker-2上,P5-3则在P5-2基础上顺推一位就行了,如果顺推的位置上已经有了副本,则继续顺推到没有当前分区副本的Broker
如果分区过多,有可能nextReplicaShift就变的挺大,在算第一个跟第二个副本的间隔的时候,不用把第一个副本算进去;
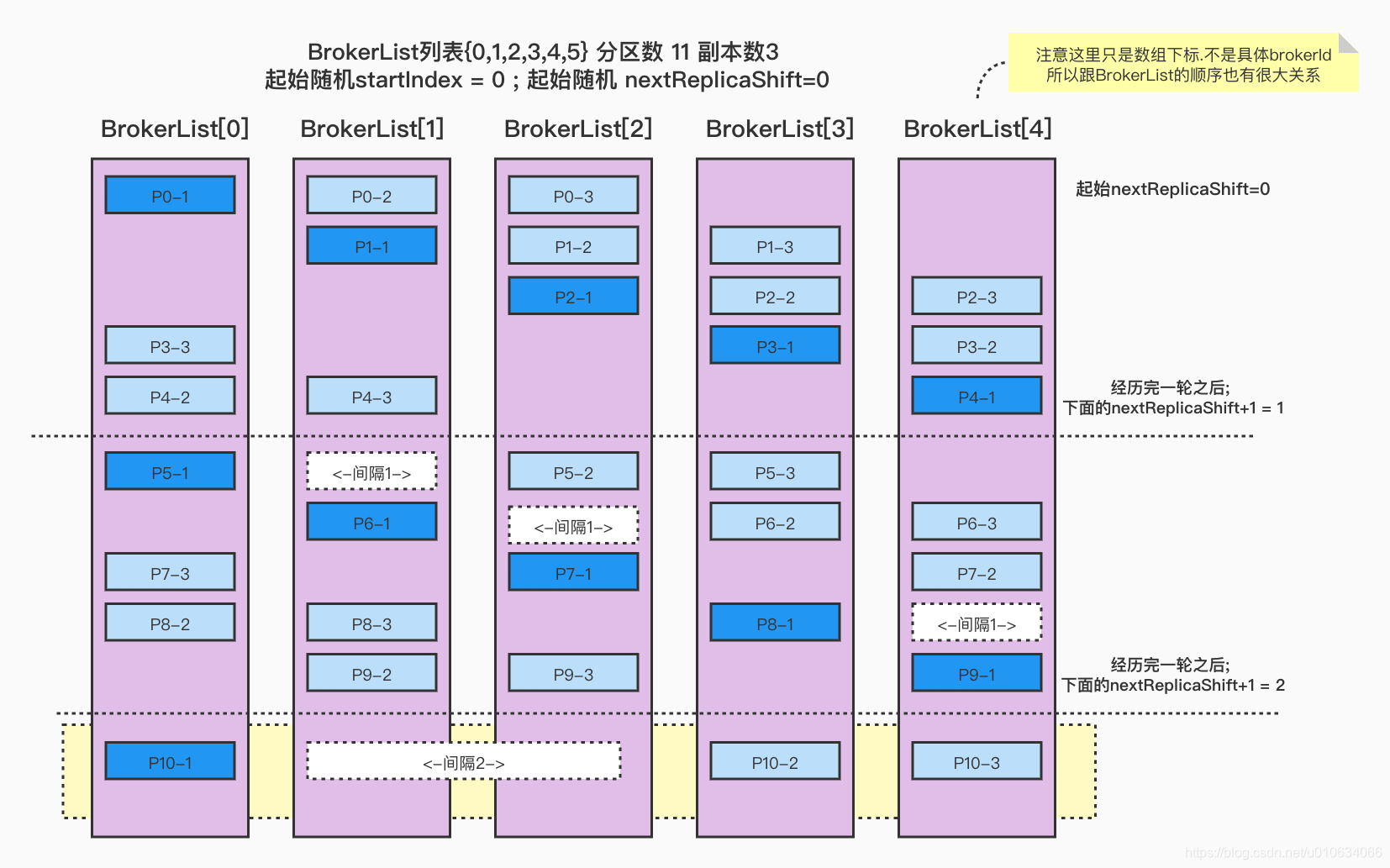
Broker列表{0,1,2,3,4} 分区数 11 副本数3 起始随机BrokerId=0; 起始随机nextReplicaShift=0 在上面基础上,再增加1个分区,你知道会怎么分配么
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 起始随机startIndex:0;起始随机nextReplicaShift:0 (p-0,ArrayBuffer(0, 1, 2)) (p-1,ArrayBuffer(1, 2, 3)) (p-2,ArrayBuffer(2, 3, 4)) (p-3,ArrayBuffer(3, 4, 0)) (p-4,ArrayBuffer(4, 0, 1)) 变更nextReplicaShift:1 (p-5,ArrayBuffer(0, 2, 3)) (p-6,ArrayBuffer(1, 3, 4)) (p-7,ArrayBuffer(2, 4, 0)) (p-8,ArrayBuffer(3, 0, 1)) (p-9,ArrayBuffer(4, 1, 2)) 变更nextReplicaShift:2 (p-10,ArrayBuffer(0, 3, 4)) (p-11,ArrayBuffer(1, 4, 0))
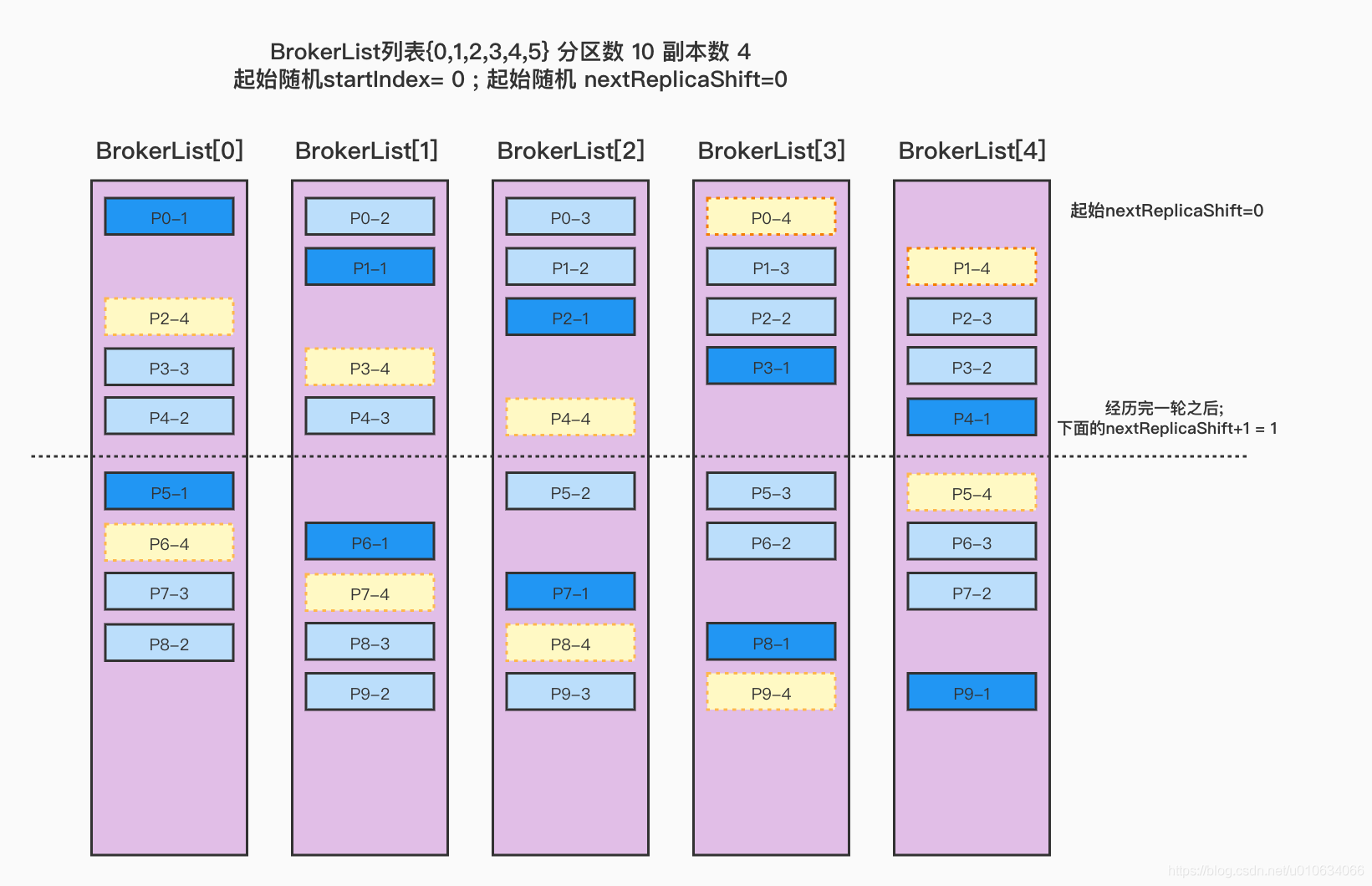
Broker列表{0,1,2,3,4} 分区数 10 副本数4 起始随机BrokerId=0; 起始随机nextReplicaShift=0 1 2 3 4 5 6 7 8 9 10 11 12 起始随机startIndex:0;起始随机nextReplicaShift:0 (p-0,ArrayBuffer(0, 1, 2, 3)) (p-1,ArrayBuffer(1, 2, 3, 4)) (p-2,ArrayBuffer(2, 3, 4, 0)) (p-3,ArrayBuffer(3, 4, 0, 1)) (p-4,ArrayBuffer(4, 0, 1, 2)) 变更nextReplicaShift:1 (p-5,ArrayBuffer(0, 2, 3, 4)) (p-6,ArrayBuffer(1, 3, 4, 0)) (p-7,ArrayBuffer(2, 4, 0, 1)) (p-8,ArrayBuffer(3, 0, 1, 2)) (p-9,ArrayBuffer(4, 1, 2, 3))
看看这里, 在上面的的副本=3的基础上,新增了一个副本=4, 原有的分配都基本没有变化, 只是在之前的分配基础上,按照顺序再新增了一个副本,见图中的 浅黄色区域 ,如果想缩小副本数量也是同样的道理;
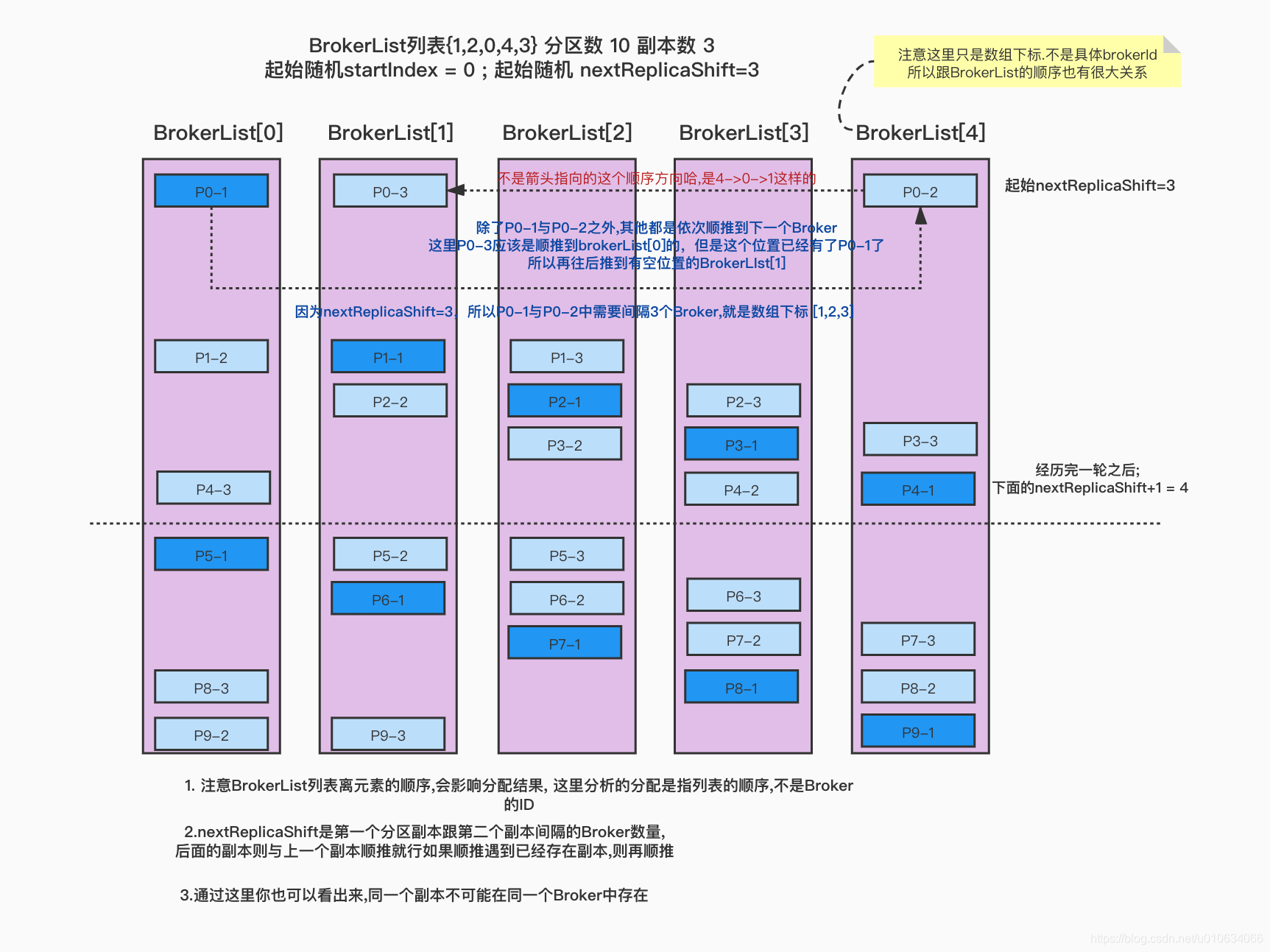
上面预设的nextReplicaShift=0,并且BrokerList顺序也是 {0,1,2,3,4} ; 这样的情况理解起来稍微容易一点; 但是再实际的分配过程中,这个BrokerList并不是总是按照顺序来的,很可能都是乱的; 所以排列的位置是按照 BrokerList的下标 来进行的;
Broker列表{1,2,0,4,3} 分区数 10 副本数3 起始随机startIndex=0; 起始随机nextReplicaShift=3
注意BrokerList列表离元素的顺序,会影响分配结果, 这里分析的分配是指列表的顺序,不是Broker的ID
nextReplicaShift是第一个分区副本跟第二个副本间隔的Broker数量,后面的副本则与上一个副本顺推就行如果顺推遇到已经存在副本,则再顺推通过这里你也可以看出来,同一个副本不可能在同一个Broker中存在
有机架方式分配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 private def assignReplicasToBrokersRackAware (nPartitions: Int, replicationFactor: Int, brokerMetadatas: Seq[BrokerMetadata], fixedStartIndex: Int, startPartitionId: Int) : Map[Int, Seq[Int]] val brokerRackMap = brokerMetadatas.collect { case BrokerMetadata (id, Some(rack) ) id -> rack }.toMap val numRacks = brokerRackMap.values.toSet.size val arrangedBrokerList = getRackAlternatedBrokerList(brokerRackMap) val numBrokers = arrangedBrokerList.size val ret = mutable.Map[Int, Seq[Int]]() val startIndex = if (fixedStartIndex >= 0 ) fixedStartIndex else rand.nextInt(arrangedBrokerList.size) var currentPartitionId = math.max(0 , startPartitionId) var nextReplicaShift = if (fixedStartIndex >= 0 ) fixedStartIndex else rand.nextInt(arrangedBrokerList.size) for (_ <- 0 until nPartitions) { if (currentPartitionId > 0 && (currentPartitionId % arrangedBrokerList.size == 0 )) nextReplicaShift += 1 val firstReplicaIndex = (currentPartitionId + startIndex) % arrangedBrokerList.size val leader = arrangedBrokerList(firstReplicaIndex) val replicaBuffer = mutable.ArrayBuffer(leader) val racksWithReplicas = mutable.Set(brokerRackMap(leader)) val brokersWithReplicas = mutable.Set(leader) var k = 0 for (_ <- 0 until replicationFactor - 1 ) { var done = false while (!done) { val broker = arrangedBrokerList(replicaIndex(firstReplicaIndex, nextReplicaShift * numRacks, k, arrangedBrokerList.size)) val rack = brokerRackMap(broker) if ((!racksWithReplicas.contains(rack) || racksWithReplicas.size == numRacks) && (!brokersWithReplicas.contains(broker) || brokersWithReplicas.size == numBrokers)) { replicaBuffer += broker racksWithReplicas += rack brokersWithReplicas += broker done = true } k += 1 } } ret.put(currentPartitionId, replicaBuffer) currentPartitionId += 1 } ret }
分区扩容是如何分配的
之前有分析过 【kafka源码】TopicCommand之alter源码解析(分区扩容)
AdminZKClient.addPartitions
1 2 3 4 5 val proposedAssignmentForNewPartitions = replicaAssignment.getOrElse { val startIndex = math.max(0 , allBrokers.indexWhere(_.id >= existingAssignmentPartition0.head)) AdminUtils .assignReplicasToBrokers(allBrokers, partitionsToAdd, existingAssignmentPartition0.size, startIndex, existingAssignment.size) }
看代码, startIndex 获取的是partition-0的第一个副本; allBrokers也是 按照顺序排列好的{0,1,2,3…}; startPartition=当前分区数;
例如我有个topic 2分区 3副本; 分配情况
1 2 3 起始随机startIndex:0currentPartitionId:0;起始随机nextReplicaShift:2;brokerArray:ArrayBuffer(0, 1, 4, 2, 3) (p-0,ArrayBuffer(0, 2, 3)) (p-1,ArrayBuffer(1, 3, 0))
我们来计算一下,第3个分区如果同样条件的话应该分配到哪里
先确定一下分配当时的BrokerList; 按照顺序的关系0->2->3 , 1->3->0 至少 我们可以画出下面的图
又根据2->3(2下一个是3) 3->0(3下一个是0)这样的关系可以知道
又要满足 0->2 和 1->3的跨度要满足一致(当然说的是在同一个遍历范围内currentPartitionId / brokerArray.length 相等)
又要满足0->1是连续的那么Broker4只能放在1-2之间了;(正常分配的时候,每个分区的第一个副本都是按照brokerList顺序下去的,比如P1(0,2,3),P2(1,3,0), 那么0->1之间肯定是连续的; )
结果算出来是 BrokerList={0,1,4,2,3} 跟我们打印出来的相符合;起始随机 nextReplicaShift = 2(P1 0->2 中间隔了1->4>2 ))
指定这些我们就可以算出来新增一个分区P3的位置了吧?
然后执行新增一个分区脚本之后,并不是按照上面分配之后的 {4,0,1} ; 而是如下
1 2 起始随机startIndex:0 currentPartitionId:2;起始随机nextReplicaShift:0;brokerArray:ArrayBuffer(0, 1, 2, 3, 4) (p-2,ArrayBuffer(2, 3, 4))
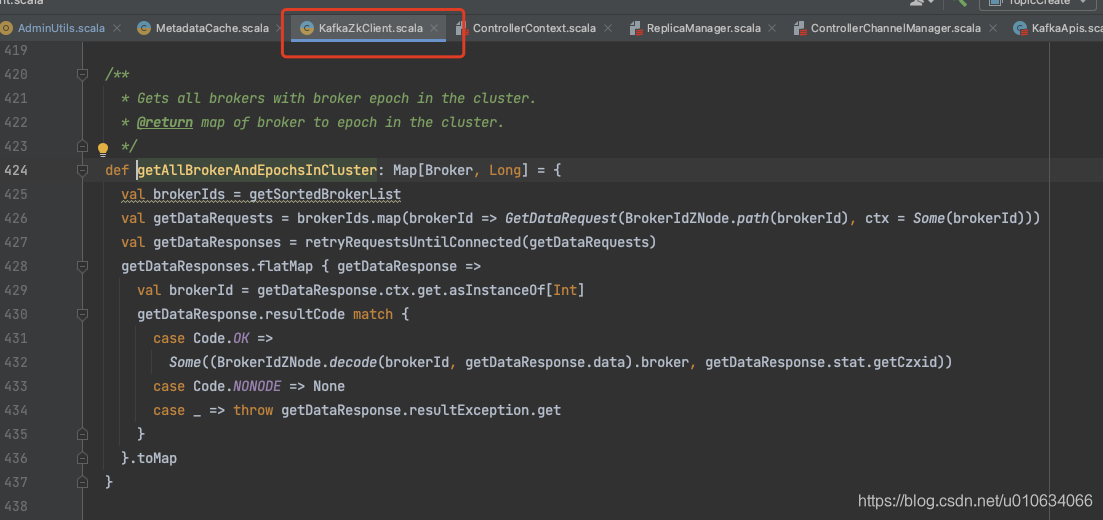
源码总结 Q&A BrokerList顺序是由什么决定的
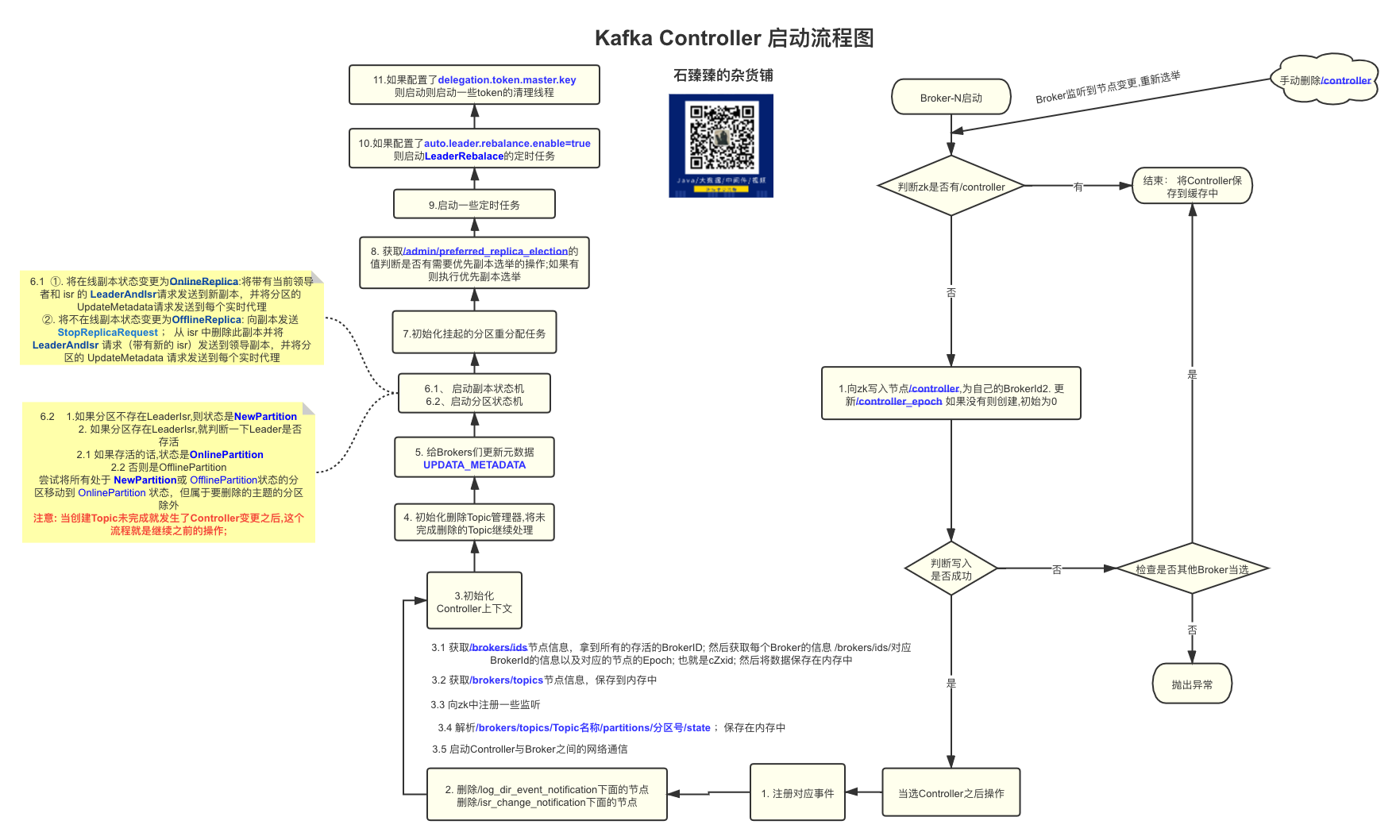
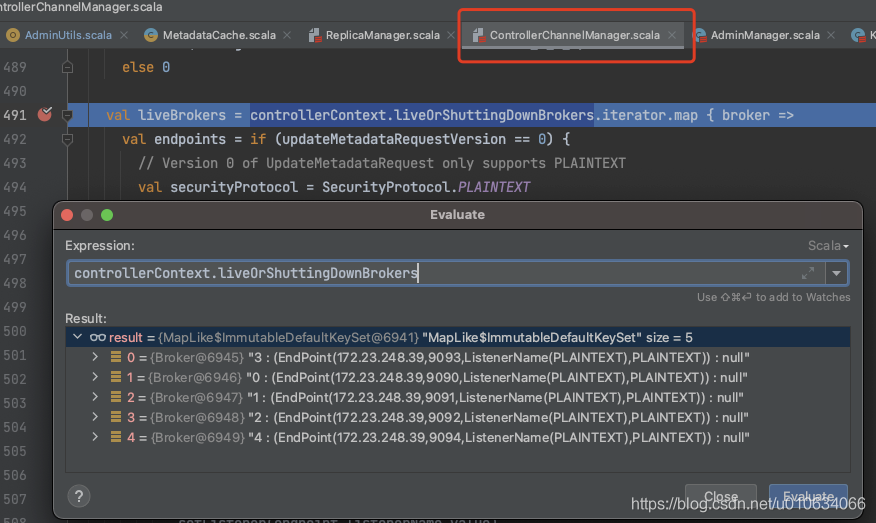
KafkaZkClient.getAllBrokerAndEpochsInCluster ; 从zk中获取Broker列表之后,虽然sort排序了,但是后面又遍历Map; 向zk发起请求,所以只要是Controller有变更之后,都会调用这个接口重新获取的Broker列表,并且每次并不一定完全一致,然后发起UPDATEMETA给所有Broker更新列表;
下面是反推调用路径;
定位 发送UPDATEMEDATA请求




 微信
微信