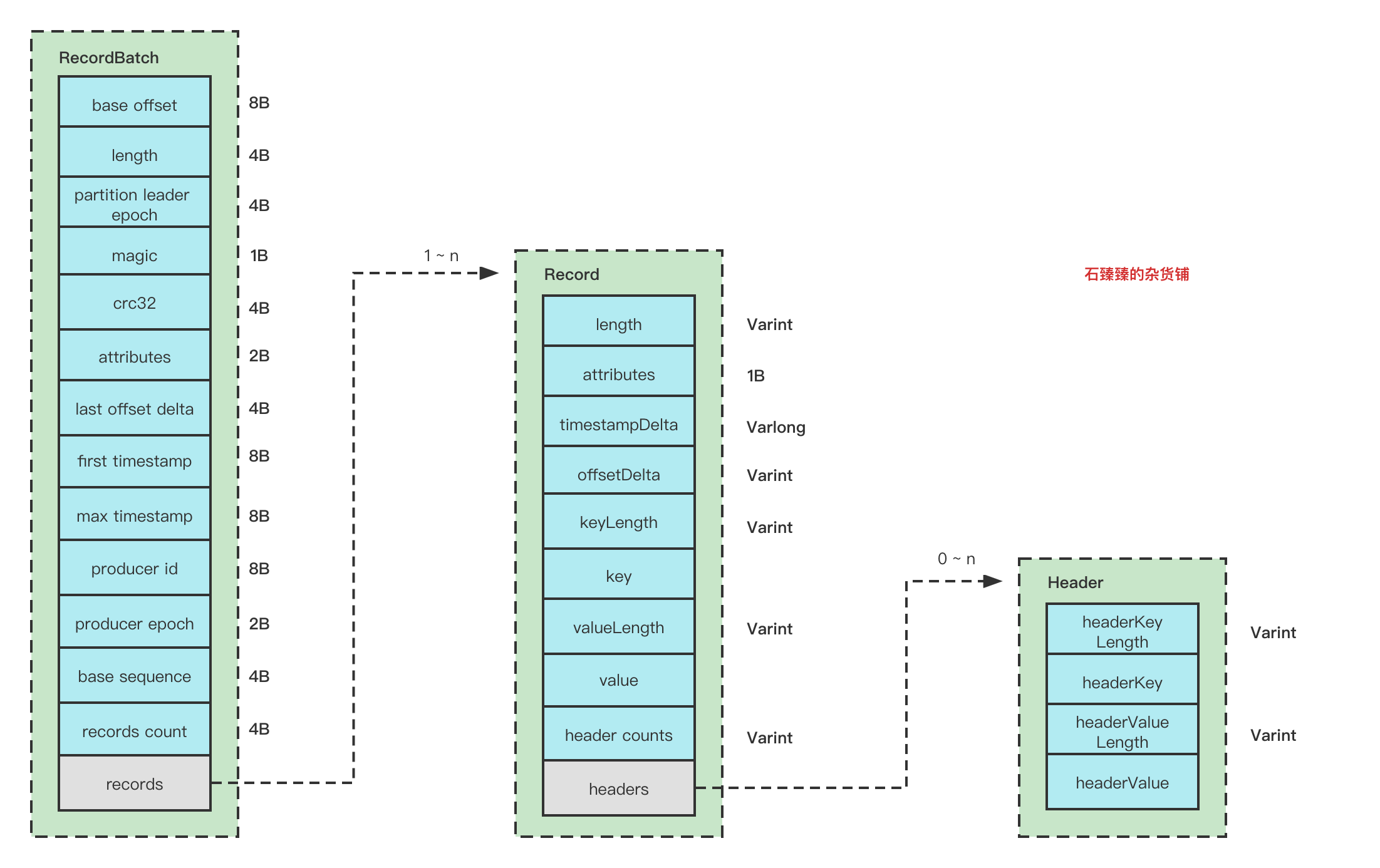
ISR伸缩机制
kafka管控推荐使用 滴滴开源 的 Kafka运维管控平台 更符合国人的操作习惯 ,
更强大的管控能力 ,更高效的问题定位能力 、更便捷的集群运维能力 、更专业的资源治理 、 更友好的运维生态
今天这篇文章你将会了解到以下几个知识点
- ISR什么时候收缩
- ISR什么时候扩展
- ISR的传播机制
温馨提示: 如果不想看分析流程可以直接看文末流程图
Kafka在启动的时候,会启动一个副本管理器ReplicaManager,这个副本管理器会启动几个定时任务。
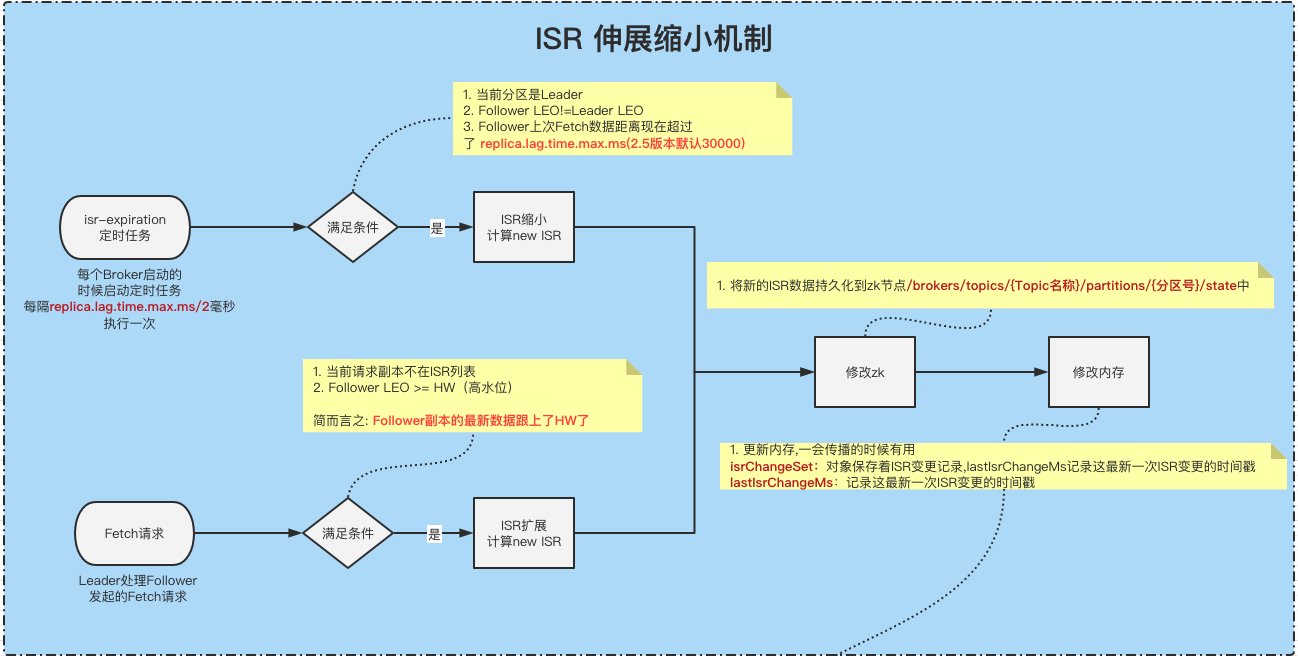
- ISR过期定时任务isr-expiration,每隔replica.lag.time.max.ms/2毫秒就执行一次。
- ISR变更的传播定时任务isr-change-propagation,每隔2500毫秒就执行一次。
replica.lag.time.max.ms : 如果一个follower在这个时间内没有发送fetch请求,leader将从ISR中移除这个follower。从2.5开始 ,默认值从 10 秒增加到 30 秒。
接下来我们分析一下这两个定时任务的作用。
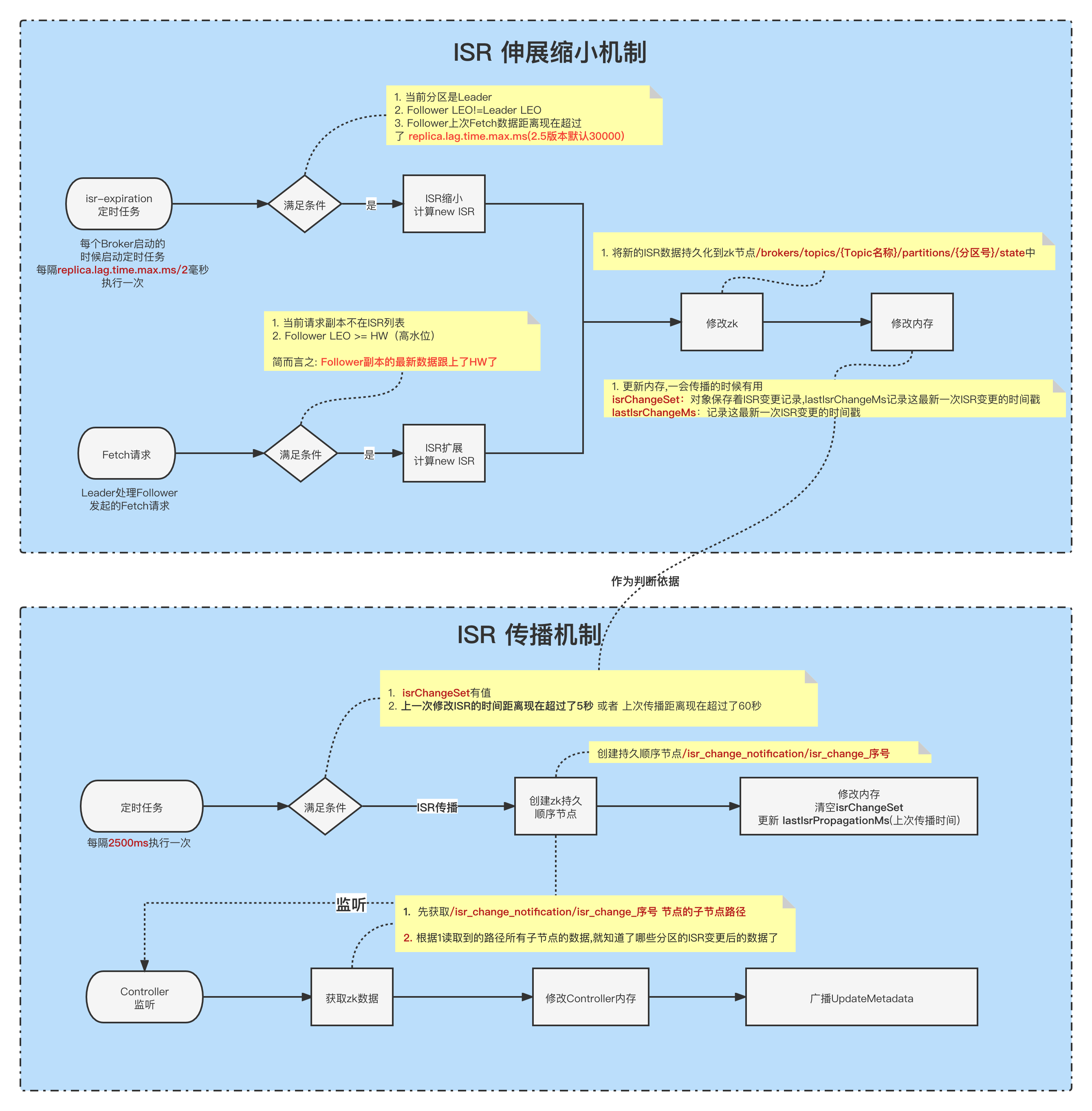
ISR收缩 isr-expiration
每隔replica.lag.time.max.ms/2毫秒执行一次
ReplicaManager#maybeShrinkIsr
1 | // 尝试收缩ISR, 遍历所有在线状态的分区,检查是否需要收缩 |
- 如上所示,先遍历所有的分区,找出所有在线的分区 进行遍历,去尝试收缩ISR。
ReplicaManager#maybeShrinkIsr
1 | /** |
找到所有需要收缩的副本OSR,判断条件:
①.当前分区必须是Leader
②.follower副本LEO!=Leader副本LEO(如果相等的话,那表示跟Leader保持最高同步了,也就没必要收缩)
③.follower副本中,当前时间 - 上一次去leader获取数据的时间戳 > replica.lag.time.max.ms(2.5版本开始默认30000ms)计算新的 newISR = 当前ISR - 1中获取到的OSR .
①. 将newISR组装一下成newLeaderData对象(还包含leader和epoche等信息),然后将信息写入到zk持久节点/brokers/topics/{Topic名称}/partitions/{分区号}/state中.
②.如果写入成功,则更新一下2个对象内存, isrChangeSet对象保存着ISR变更记录,lastIsrChangeMs记录这最新一次ISR变更的时间戳。一会这两个两个对象,在ISR传播的时候需要用到。
③.如果写入成功,则更新一下2个对象内存,inSyncReplicaIds=newISR, zkVersion = newVersion。尝试增加HW(高水位), maybeIncrementLeaderHW 这个方法可能会在 ①.ISR变更 ②.任何副本的LEO更改 这两种情况下触发调用。当然我们这种场景触发是因为ISR变更了。如果HW有更新,则返回true,否则返回false,具体逻辑,请看下面。
如果3中更新成功,则触发一下待处理的延迟操作。这里包含一些fetch、produce、deleteRecords等延迟请求。
增加HW(高水位)的逻辑
Partition#maybeIncrementLeaderHW
1 | /** |
遍历所有的副本,找到 所有在ISR中的副本和 上一次Fetche数据距离现在<=replica.lag.time.max.ms时间但是还没有来得及进入ISR列表的副本, 然后从这些副本中找到最小的LEO newHW.
如果newHW > 当前Leader的LEO,抛异常,这种情况有问题。
将newHW 和 oldHW做个对比,如果满足下面任意一个条件,则更新 HW的值,否则不更新。
①.oldHW.messageOffset < newHW.messageOffset(新的HW>旧的HW)
②.oldHW.messageOffset==newHW.messageOffset&&oldHW.onOlderSegment(newHW)。这里解释一下,当LogSegment滚动到新的Segment的时候,就会出现这种情况,更新一下HW(因为日志段变成新的了)
ISR 扩展
ISR的缩小,是有一个定时任务定时检查,而ISR扩展可不一样,它是在Follower副本向Leader副本发起 Fetch请求请求的时候会尝试检查是否需要重新加入到ISR中。
当发现Follower副本不在ISR列表的时候,就会执行下面的方法。
Partition#maybeExpandIsr
1 | /** |
- 检查当前发起 Fetch请求 请求的Follower副本是否满足加入ISR的条件, 条件如下(与运算):
①. 当前副本不在ISR列表中
②. Follower的LEO>=HW(高水位) && Follower的LEO>= 当前Leader的LogStartOffset - 如果满足条件,则开始执行 ISR扩展的流程,这里的流程跟上面 ISR缩小 的时候差不多。
①. 将newISR组装一下成newLeaderData对象(还包含leader和epoche等信息),然后将信息写入到zk持久节点/brokers/topics/{Topic名称}/partitions/{分区号}/state中.
②.如果写入成功,则更新一下2个对象内存, isrChangeSet对象保存着ISR变更记录,lastIsrChangeMs记录这最新一次ISR变更的时间戳。一会这两个两个对象,在ISR传播的时候需要用到。
③.如果写入成功,则更新一下2个对象内存,inSyncReplicaIds=newISR, zkVersion = newVersion。
那么, 上面的ISR伸缩,只是去zk上修改了ISR的数据和Controller里面的内存数据。
啥时候通知对应的Broker ISR已经变更了呢?
接下来我们来看看 ISR的广播
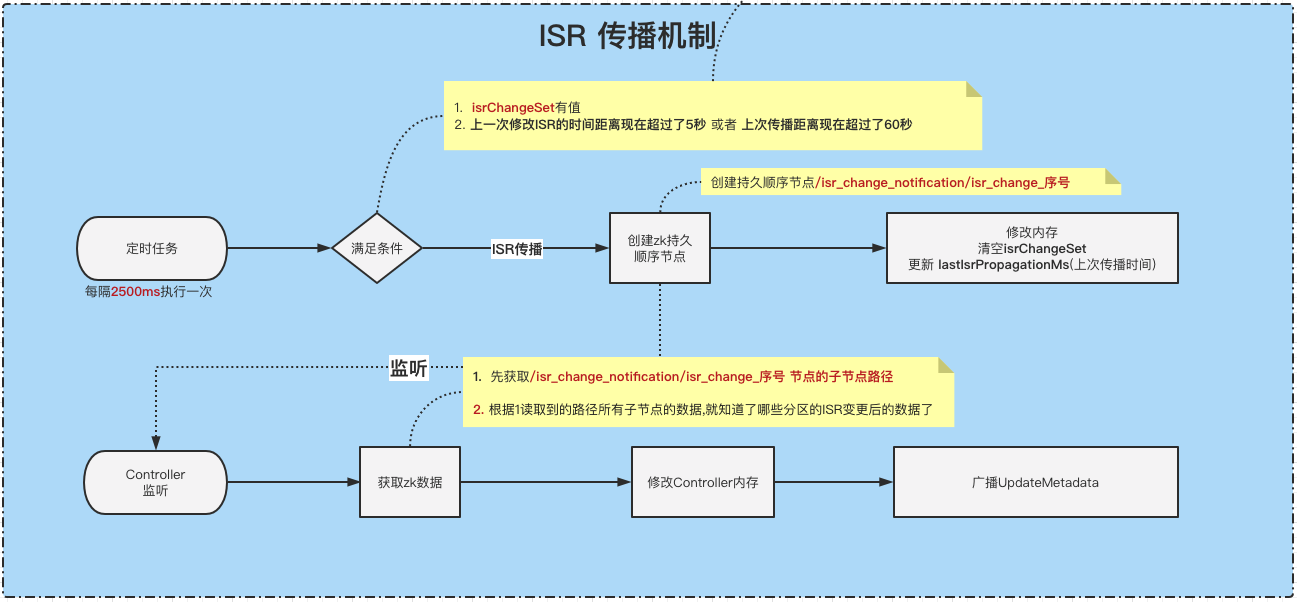
传播ISR maybePropagateIsrChanges
每隔2500毫秒就执行一次。
上面的ISR的收缩和扩展,最终呈现的结果是 修改ISR和内存,但是并没有通知到每个Broker。
只修改zk中的/brokers/topics/{Topic名称}/partitions/{分区号}/state节点,并不会通知集群,ISR已经变更了,因为正常情况下,Broker是没有去监听每一个state节点的。
因为在整个集群中,state节点太多了,一个分区一个,每个节点都去监听的话成本有点高
除了在分区副本重分配的时候,会去监听迁移的state节点,其他情况都没有监听。
那么,我们如何通知其他Broker ISR 变更了呢?
答案是:定时任务定时去传播ISR的变更。
ReplicaManager#maybePropagateIsrChanges
1 | /** |
- 判断是否满足传播条件,条件为下(同时满足)
①. 判断isrChangeSet不为空值,这里的isrChangeSet就是我们上面ISR收缩成功之后装填的值。
②. (lastIsrChangeMs(上次ISR变更时间) + 5000 < 当前时间)或者(<font color=red size=3>lastIsrPropagationMs(上次传播时间)</font> + <font color=red size=3>60000</font>< 当前时间)
总结: 有ISR变更过了&&(上一次ISR变更时间距离现在超过了5秒 || 上次传播时间距离现在超过了60秒)。
这避免了短时间内多次ISR变更发起多次传播。 当超过60秒都没有发起过传播,则立马发起传播。
- 开始传播!
传播的方式就是,创建一个顺序的持久节点/isr_change_notification/isr_change_序号,节点内容就是 isrChangeSet。 - 清空isrChangeSet,更新 lastIsrPropagationMs(上次传播时间)
PS:这里注意, 在kafka_2.7 版本之后,传播方式以及不是通过写入zk节点的方式,改成了定时向Controller发起AlterIsrRequest请求的方式了,具体情况 KIP-497
Controller监听/isr_change_notification/子节点
上面我们说因为正常情况下,Broker是没有去监听每一个state节点的(除了分区副本重分配),那么为了避免监听多个节点,只要有ISR变更就创建了/isr_change_notification/isr_change_序号节点,Controller只需要监听这个节点就可以指定哪个ISR变更了。
这个跟动态配置那一块的处理逻辑是一样的。
KafkaController#processIsrChangeNotification
1 | private def processIsrChangeNotification(): Unit = { |
- 去zk获取/isr_change_notification节点的所有zk节点
- 根据获取到的子节点路径,然后再去zk读取这些子节点的数据
- 第2步骤拿到的是分区号,这时候根据分区号去对应的/brokers/topics/{Topic名称}/partitions/{分区号}/state节点读取新的数据, 然后将新的数据重载到当前Controller的内存中。
- 向所有Broker发 UpdateMetadata 请求
- 删除/isr_change_notification节点下面的数据。
总结
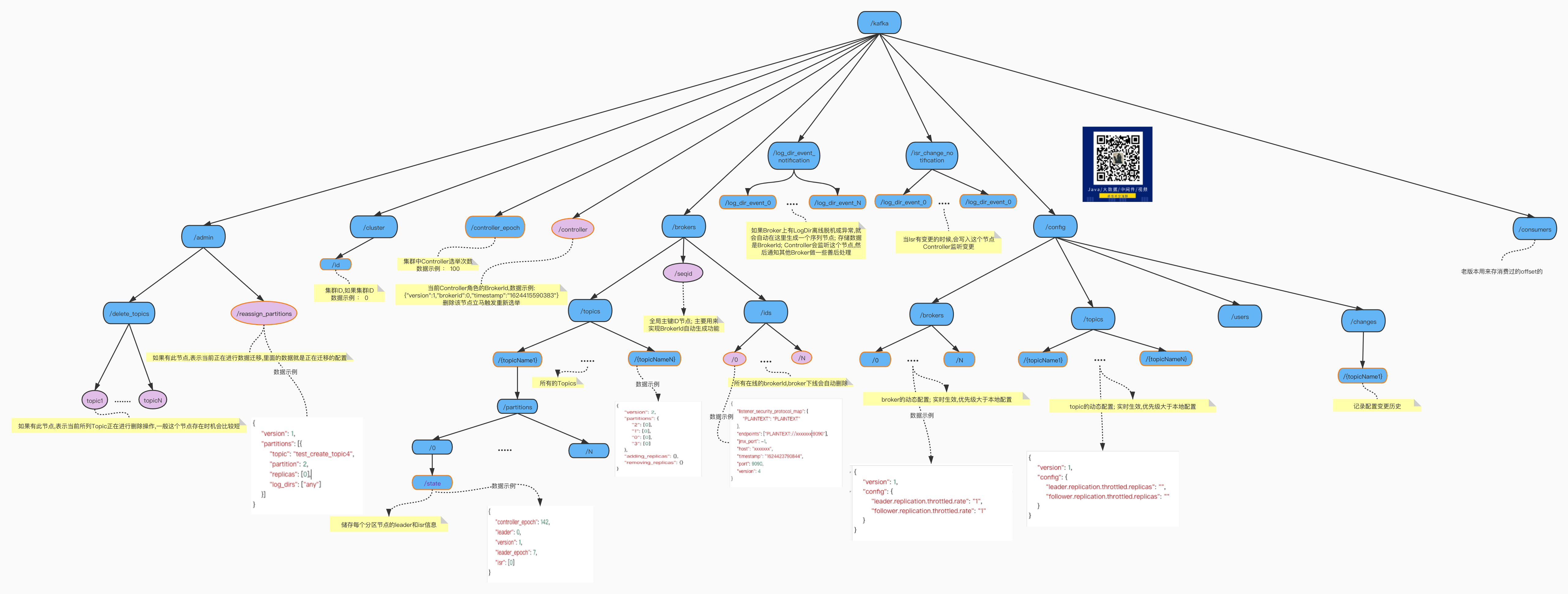
如下图, 图看不清的话点击 阅读原文
作者石臻臻,工作8年的互联网老兵,丰富的开发和管理经验,全网「 粉丝数4万 」,
先后从事 「 电商 」、「 中间件 」、「 大数据」 等工作
现在任职于「 滴滴技术专家 」岗位,从事开源建设工作
目前在维护 个人公众号「 石臻臻的杂货铺 」 ; 关注公众号会有「 日常送书活动 」;
欢迎进「 高质量 」 「 滴滴开源技术答疑群 」 , 群内每周技术专家轮流值班答疑
可帮忙「 内推 」一二线大厂

 微信
微信



石臻臻的杂货铺
Java/大数据/中间件/教学视频