kafka生产环境磁盘坏掉了的正确处理姿势,建议收藏以备不时之需
kafka管控推荐使用 滴滴开源 的 Kafka运维管控平台 更符合国人的操作习惯 ,
更强大的管控能力 ,更高效的问题定位能力 、更便捷的集群运维能力 、更专业的资源治理 、 更友好的运维生态
最近,有位朋友找我,向我求助,说他生产环境出事故了,帮他解决一下。
就瞅他这个态度,各位德华、朝伟、志玲们, 是不是应该把他先T出群聊再拉黑 [奸笑] 。
好,话不多说,生产环境的事故,时间就是金钱(请这位同学一会给我结个账),来、咋们就一起来帮他看一看。
问题描述
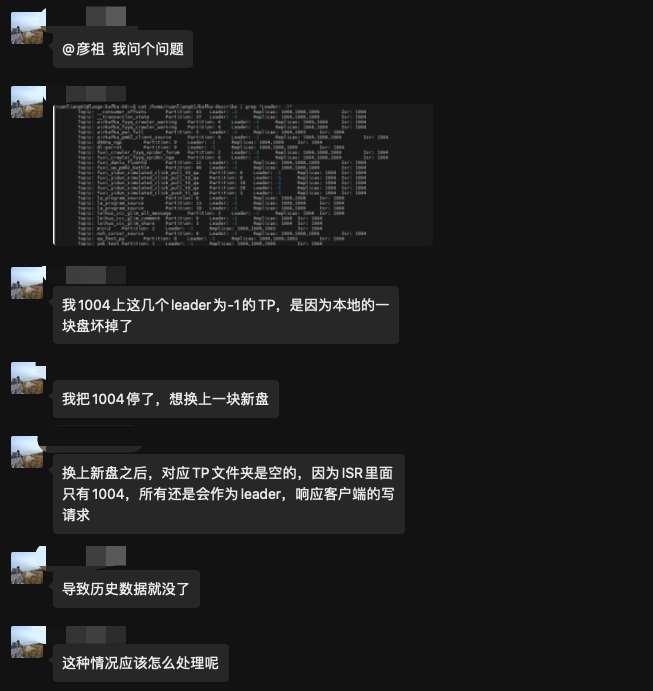
当事人的问题描述
问题整理
- Broker 1004 上面的一块磁盘坏掉了。
- 坏的透透的,也没有RAID,反正就是这块磁盘数据恢复不了了。
- 因为1004坏了,导致副本离线,如果副本刚好是Leader,则会触发Leader重选举。
- 然后刚好有一些分区中的ISR只有1004,这个时候1004副本下线,重选举的时候Leader选不出来,就变成了-1,这些分区此时为不可用状态,需要里面恢复。(关于Leader选举请看Kafka 分区Leader选举流程和选举策略)
- 如果直接停机1004更换磁盘重启,那么势必会造成数据全部丢失、
- 分区都是3副本
彦祖,应该怎么办?才能将损失降到最低啊!
分析问题
磁盘不是RAID,不能容错,想恢复数据是不大可能了,这里我们不考虑其他一些方式恢复磁盘。
一般来说,Kafka的多副本就是用来应对这种情况的,Follower副本用来备份容错,这里分区都是3个副本,既然1004中的副本丢失了,没有关系,还有其他副本的数据。
但是坏就坏在,有一些分区的Follower不在ISR里面,ISR表示的是同步副本,跟Leader保持较高的同步,如果配合ack=all,可以达到最高的可靠性。
ISR里面只有1004,如果贸然停机1004,换上新盘,再重启会造成什么情况?
会造成数据全部丢失
如果你还记得我上一篇的文章Kafka 分区Leader选举流程和选举策略 ,你就会知道,当1004再次重启的时候,他会再次当选为Leader, 那么其他的Follower副本就会去同步Leader,发现自己的数据跟Leader不一致就会截断自己的数据,这个时候Leader没有数据,Follower截断之后,那就全没了。
那我让其他副本当选为Leader是不是就可以避免上面的问题了?
嗯,没错,为了避免上面的问题,我们只能先让其他的副本当选Leader了。
那么,如何选举其他副本为Leader呢?
- 所有的选举策略最基本的逻辑是 副本在线&&副本在ISR 内,但是有一种情况例外
当配置了脏选举,或者主动执行脏选举命令的时候,不在ISR内也可以当选,所以执行一次脏选举就可以。 - 手动修改ISR里面的数据
解决问题
解法一:
- 停止Broker-1004,换上新的磁盘
- 执行一次脏选举 kafka-leader-election.sh –UNCLEAN
- 执行完毕之后,会从之前的Follower副本里面选出一个作为Leader
- 稍等片刻,等1004掉出ISR列表之后,再重启1004这台机器。
- 1004重启之后,开始向Leader同步数据,因为是新的磁盘,还没有任何数据,会自动重建。
这里有几个点需要大家思考一下:
当上面步骤3执行完毕之后,新的Leader选出来了,作为原来就在ISR列表中的 broker-1004 会掉出ISR列表吗?
答案是 “会” ! 这里涉及到ISR的伸缩机制。
简单来说就是,每个Broker都会有一个 isr-expiration缩小定时任务,定时去检查是否满足ISR缩小的条件,每隔replica.lag.time.max.ms/2 (2.5版本开始默认30000) 毫秒执行一次
其中一个条件就是,找到当前Broker所有在线的Leader分区
回到我们这个问题,当新的Leader选举出来之后,启动了定时任务之后,就会发现之前在ISR列表内的1004,已经慢慢脱离ISR
有同学表示,是否可以指定某个副本当选Leader,比如Follower副本中我想挑选一个最大LEO当选Leader,是不是可以将损失降到更低!
解法二:
Follower副本中我想挑选一个最大LEO当选Leader,是不是可以将损失降到更低!
首先,能用这种方案,那么前提肯定 acks!=all
因为acks!=all 的情况,已经确保了isr列表里面的的数据都是一致的。
但是话又说回来,你既然acks!=all,也就相当于你已经允许一定量的数据发生丢失。
所以丢多一点和丢少一点很重要吗(极小的差别)
官方Leader选举策略都是按照AR的顺序来选择,是因为它需要保证Leader的均衡(为何是保证的leader均衡请看分区副本分配策略), 这才是首要的,想要确保数据不丢失请设置acks=all
另外,判断Follower的LEO大小,是需要再源码层级调用才知道,那么就需要改源码了。
你想通过recovery-point-offset-checkpoint来判断LEO的大小是不准确的,这个是记录的分区写入磁盘的offset,每个Broker写入时机你也不清楚(操作系统控制什么时候将PageCache写入磁盘),所以不能保证100%的准确性。
那你说,你一定要这样做(可以但没有必要),那我也给你提供这么一个思路。(非源码层面的)
- 停止Broker-1004,换上新的磁盘
- 从Broker中找到你想要这么做的分区,查看recovery-point-offset-checkpoint文件比较一下,找到最大LEO的副本,这里你可能会有很多个分区
- 修改zk中/brokers/topics/{Topic名称}/partitions/{分区号}/state节点,把ISR改成只剩下你想要设为leader的副本id。
- 因为Controller平时不会监听state节点,所以你还需要再创建一个/isr_change_notification/isr_change_序号 节点,触发Controller的监听,让他能触发Controller更新内存,还有给brokers发送UpdateMetadata请求
例如: /isr_change_notification/isr_change_0000000001
1 | // 这个表示的是 Topic2的0号分区 有ISR的变更 |
- 改了ISR之后,仍旧不会触发Leader选举,所以这个时候我们可以手动触发一下kafka-leader-election.sh –UNCLEAN ,仍旧是脏选举哦,PREFERRED只会选择AR的第一个为Leader。
- 稍等片刻,等1004掉出ISR列表之后,再重启1004这台机器。
- 1004重启之后,开始向Leader同步数据,因为是新的磁盘,还没有任何数据,会自动重建。
上面有关怎么修改节点,节点格式应该是什么样子的,具体详情请看 ISR伸缩机制
最后再说一句:除非你非常清楚自己在做什么,否则不要这么干,吃力不讨好的事情。
作者石臻臻,工作8年的互联网老兵,丰富的开发和管理经验,全网「 粉丝数4万 」,
先后从事 「 电商 」、「 中间件 」、「 大数据」 等工作
现在任职于「 滴滴技术专家 」岗位,从事开源建设工作
目前在维护 个人公众号「 石臻臻的杂货铺 」 ; 关注公众号会有「 日常送书活动 」;
欢迎进「 高质量 」 「 滴滴开源技术答疑群 」 , 群内每周技术专家轮流值班答疑
可帮忙「 内推 」一二线大厂

 微信
微信






石臻臻的杂货铺
Java/大数据/中间件/教学视频